EfficientSAM
Model from Meta. Paper
It is essentially the same as the MobileSAM model, but with a Masked Pretraining objective.
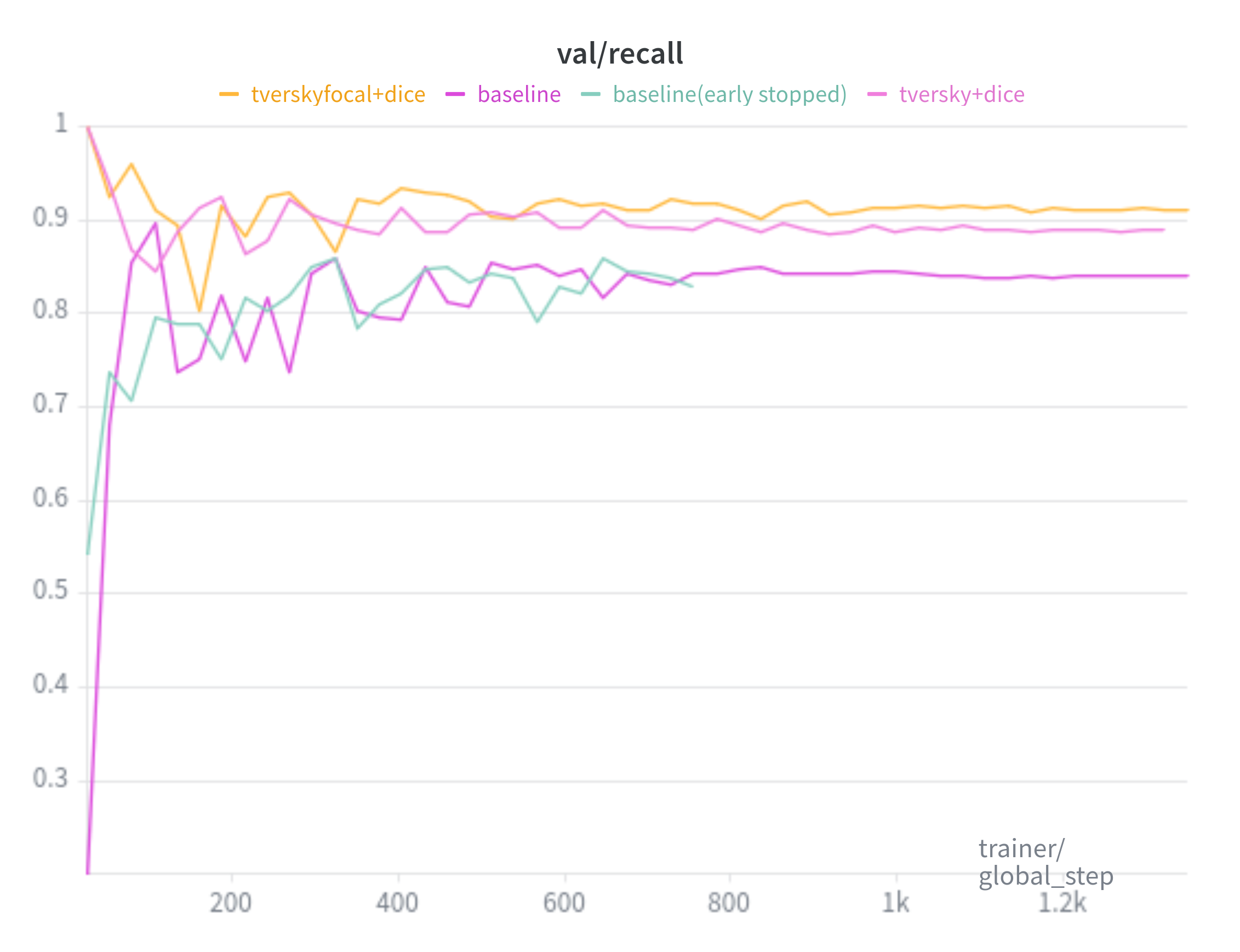
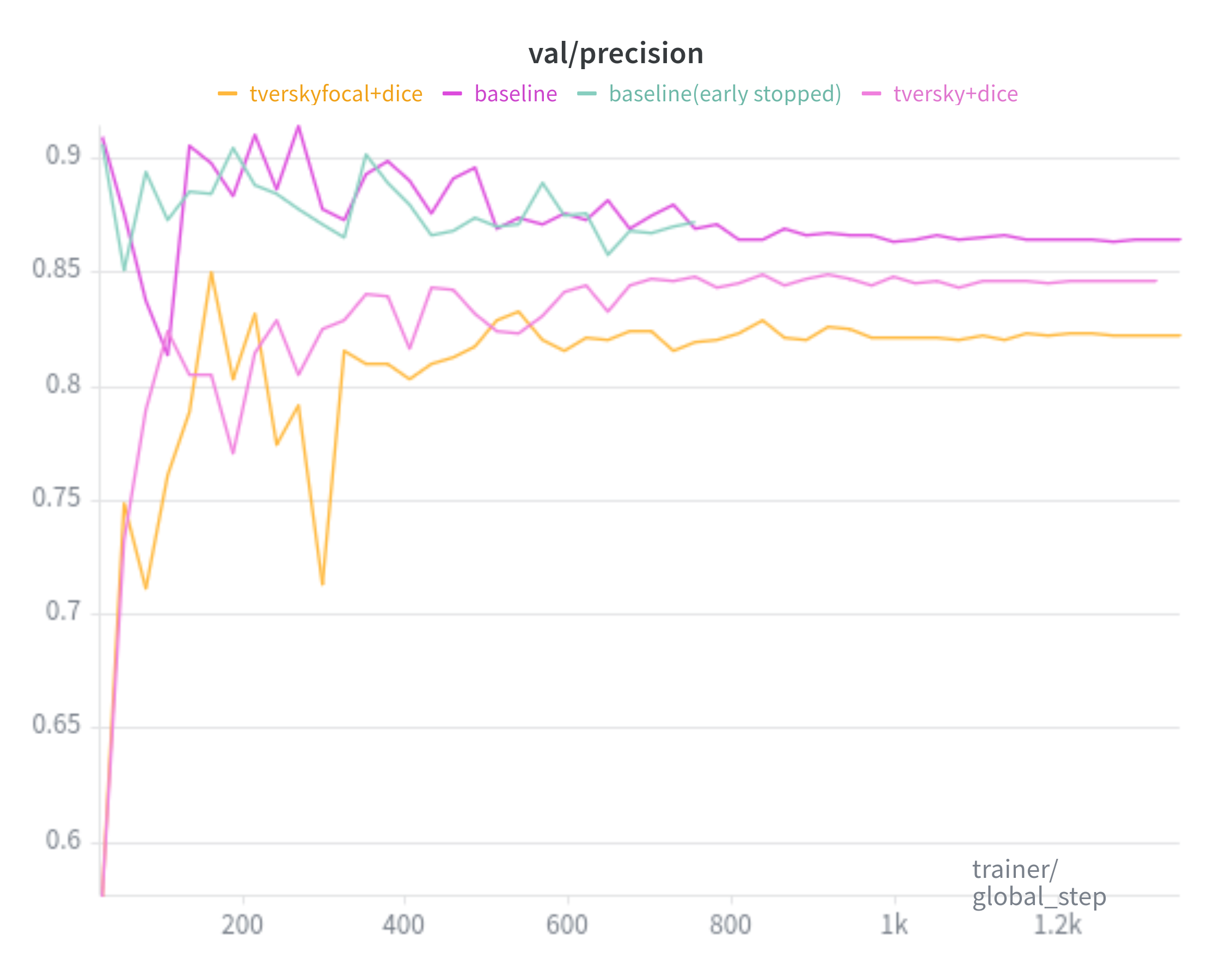
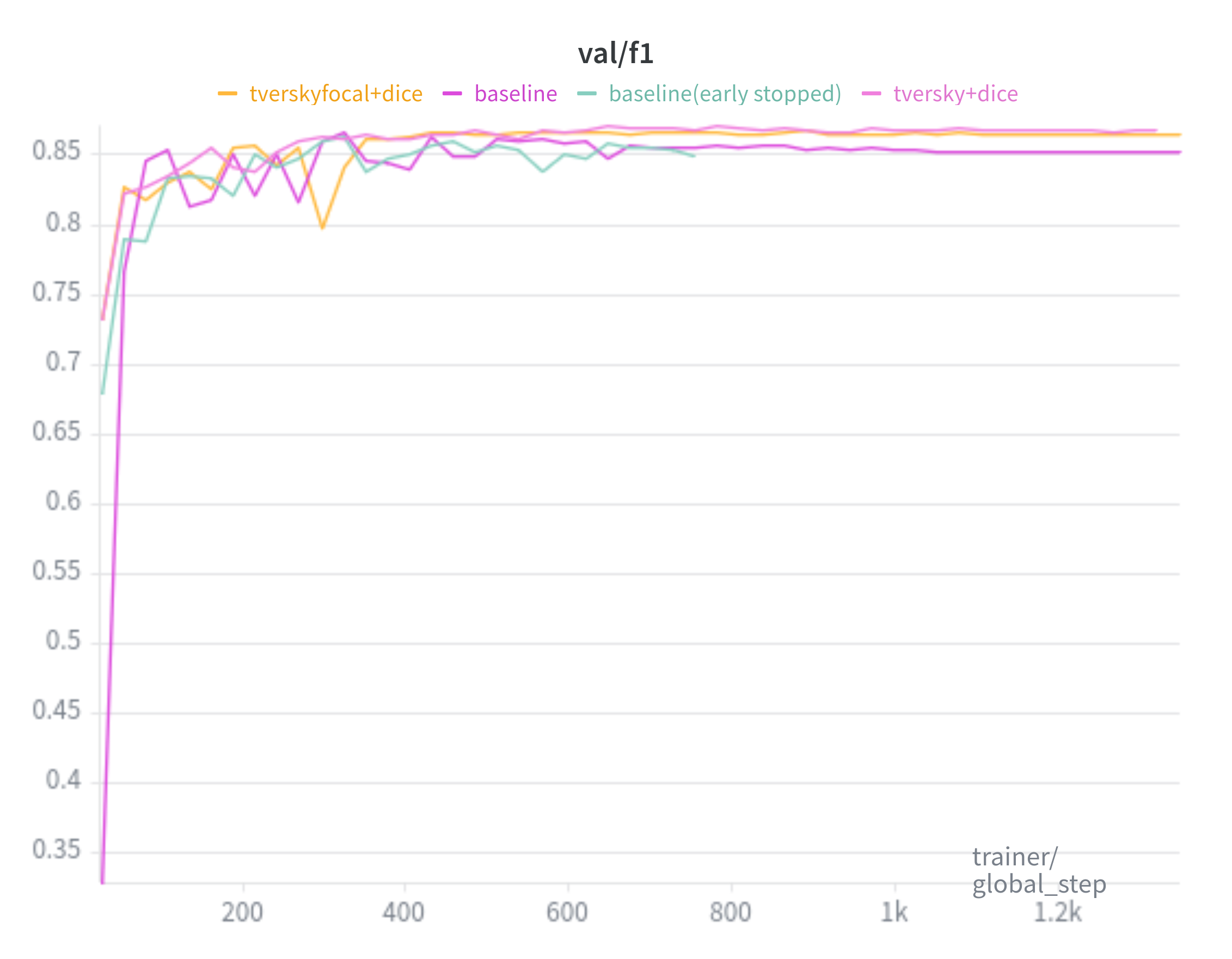
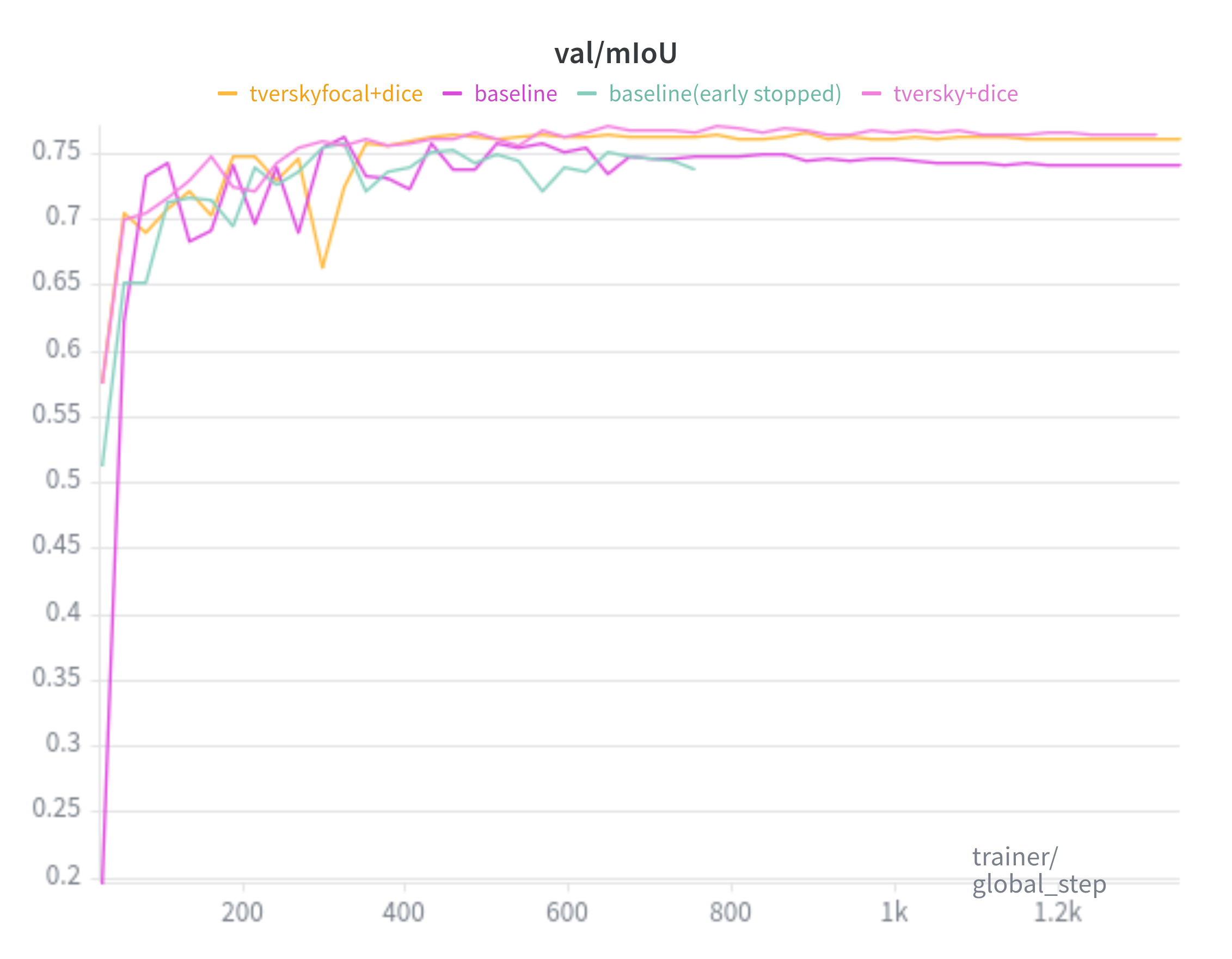
Baseline is trained with the SAM loss(20:1 ratio of Focal Loss and Dice Loss, respectively). TverskyFocal+Dice trained with 7:3 TverskyFocal Loss and Dice Loss. Tversky+Dice trained with 7:3 Tversky Loss and Dice Loss.
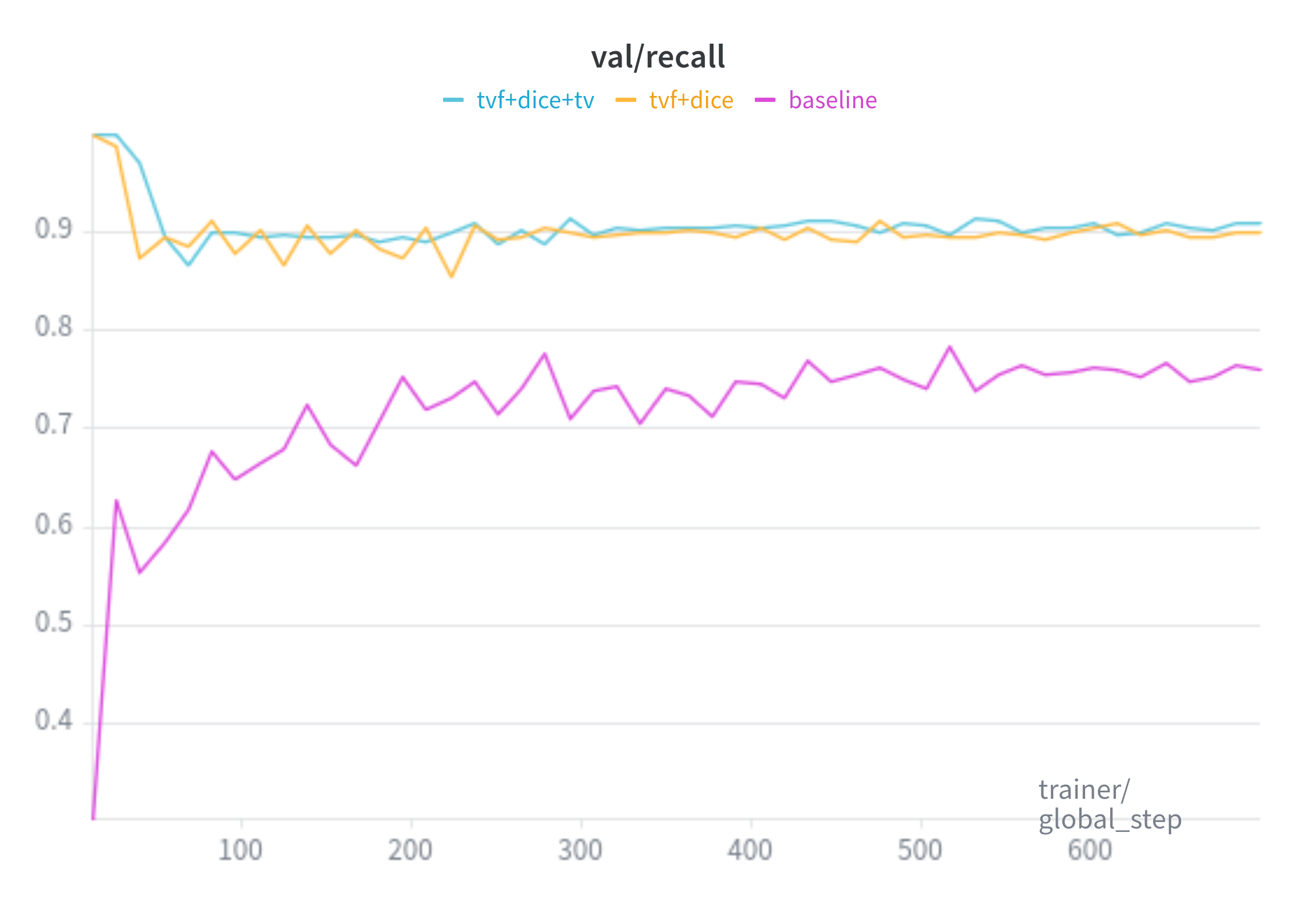
Recall:
Precision:
F1:
mIoU:
MobileSAM
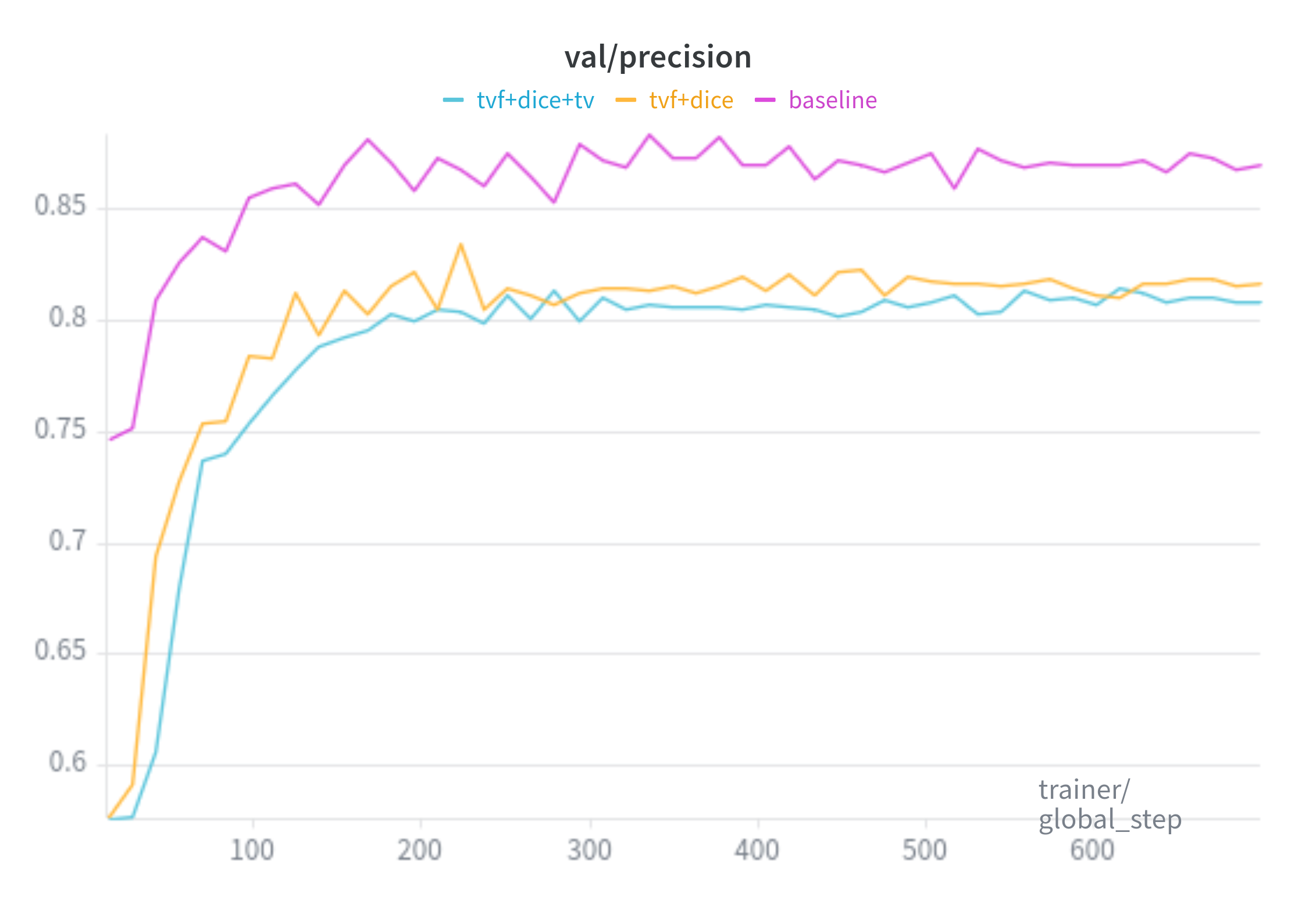
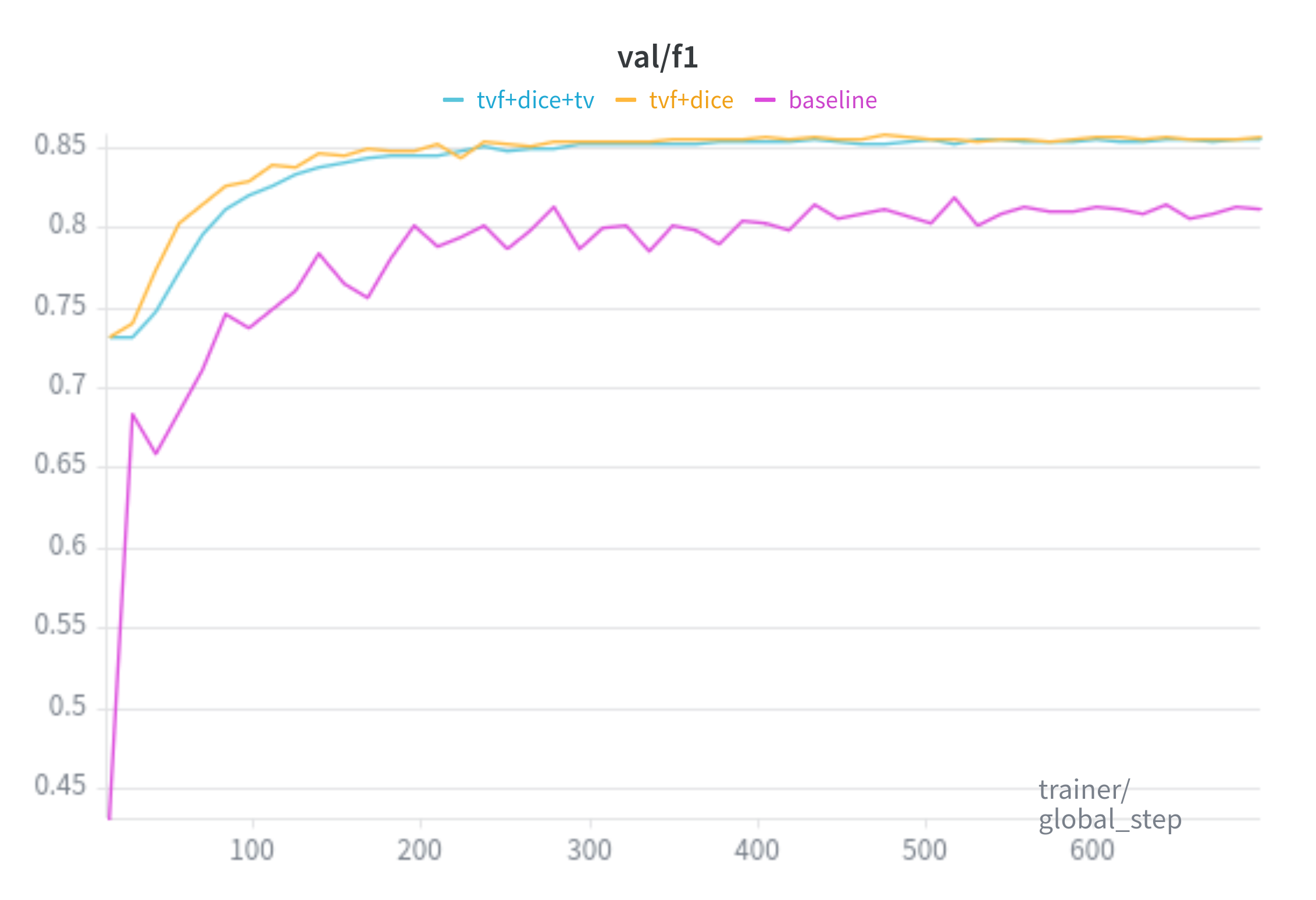
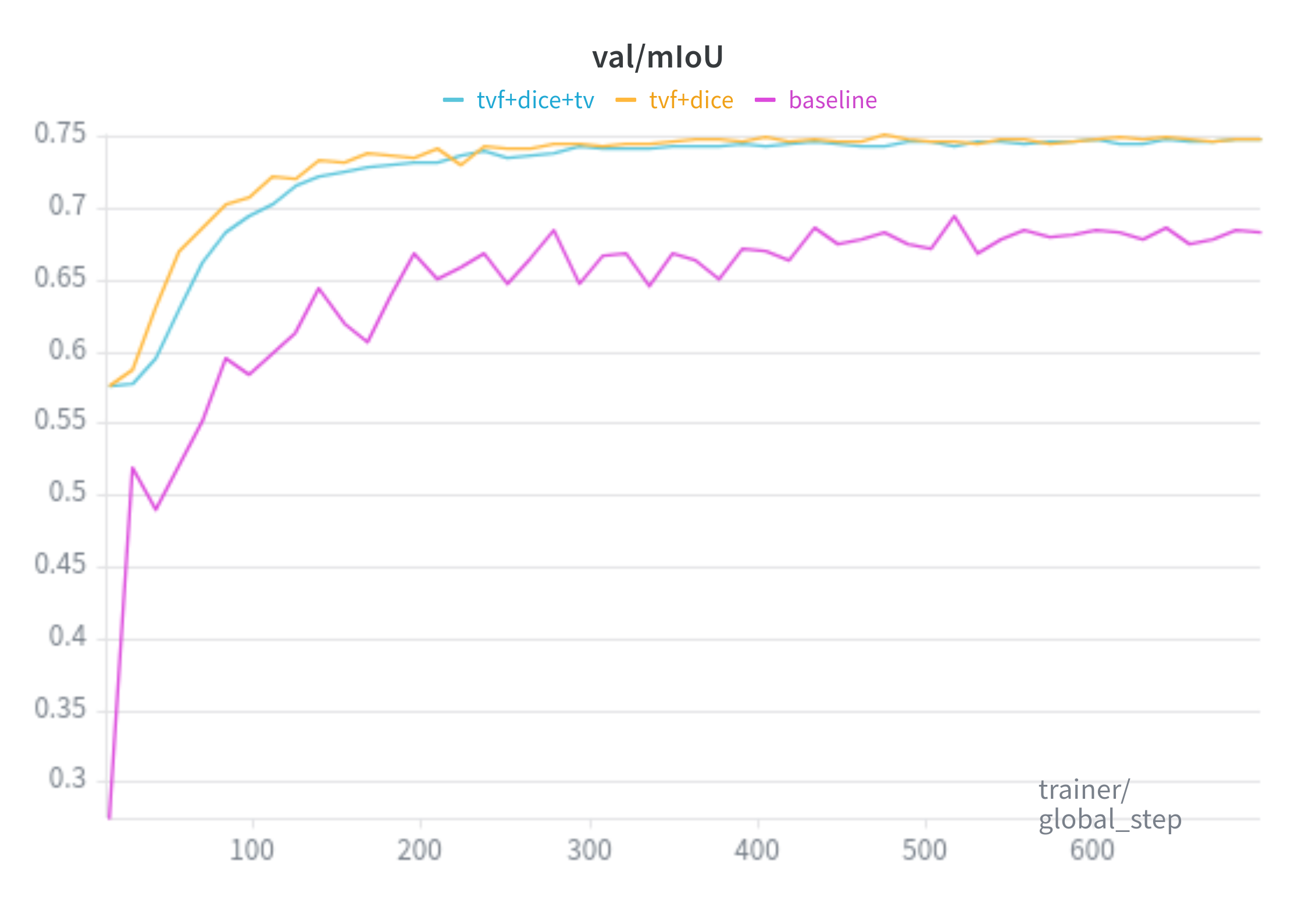
Baseline is trained with the SAM loss(20:1 ratio of Focal Loss and Dice Loss, respectively).
Recall:
Precision:
F1:
mIoU:
Normal SAM
Baseline for SAM models is trained with the 20:1 ratio of Focal loss and Dice loss(from paper).
TverskyFocal+Dice is trained with 7:3 ratio of TverskyFocal and Dice loss.
All Models
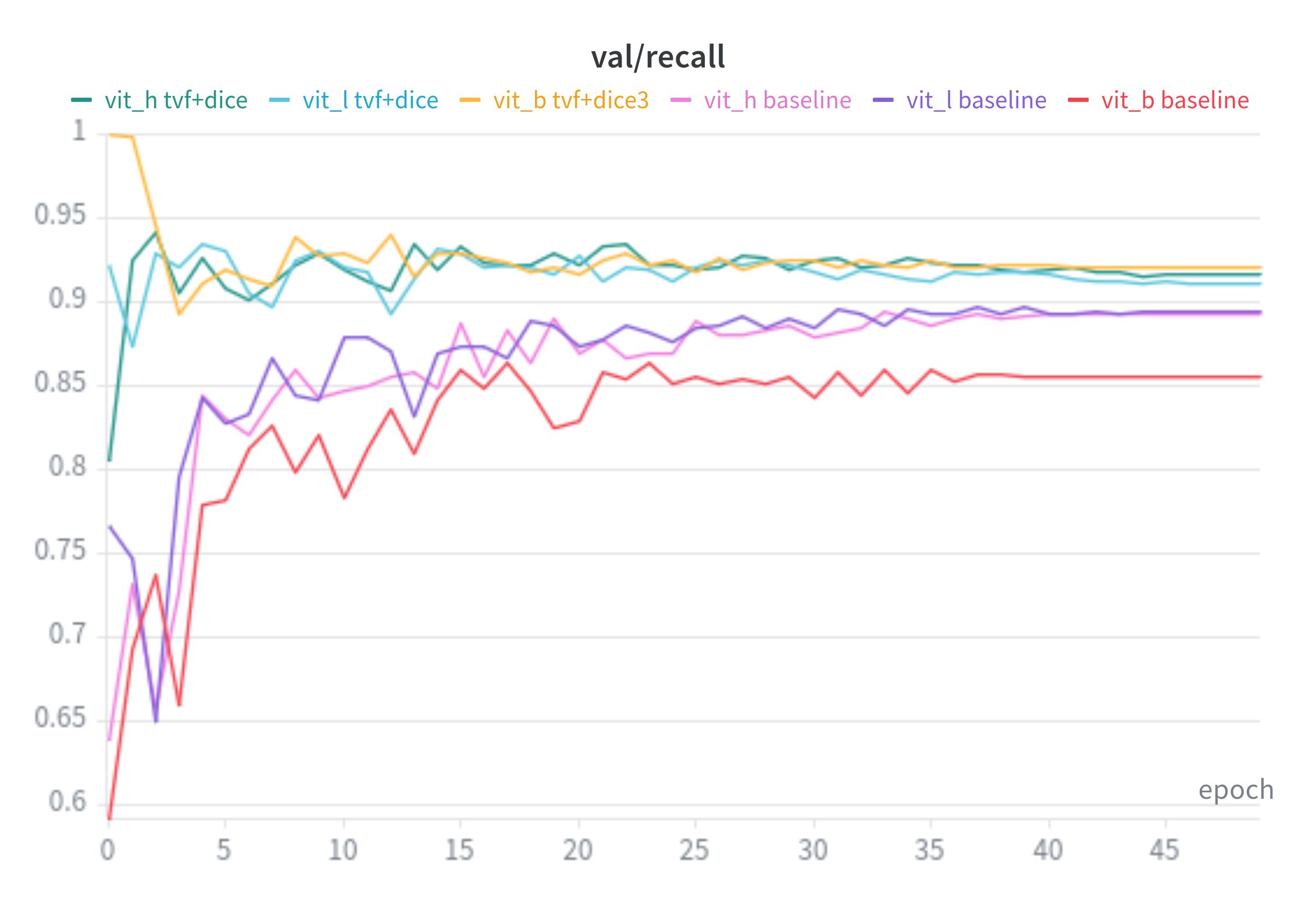
Recall:
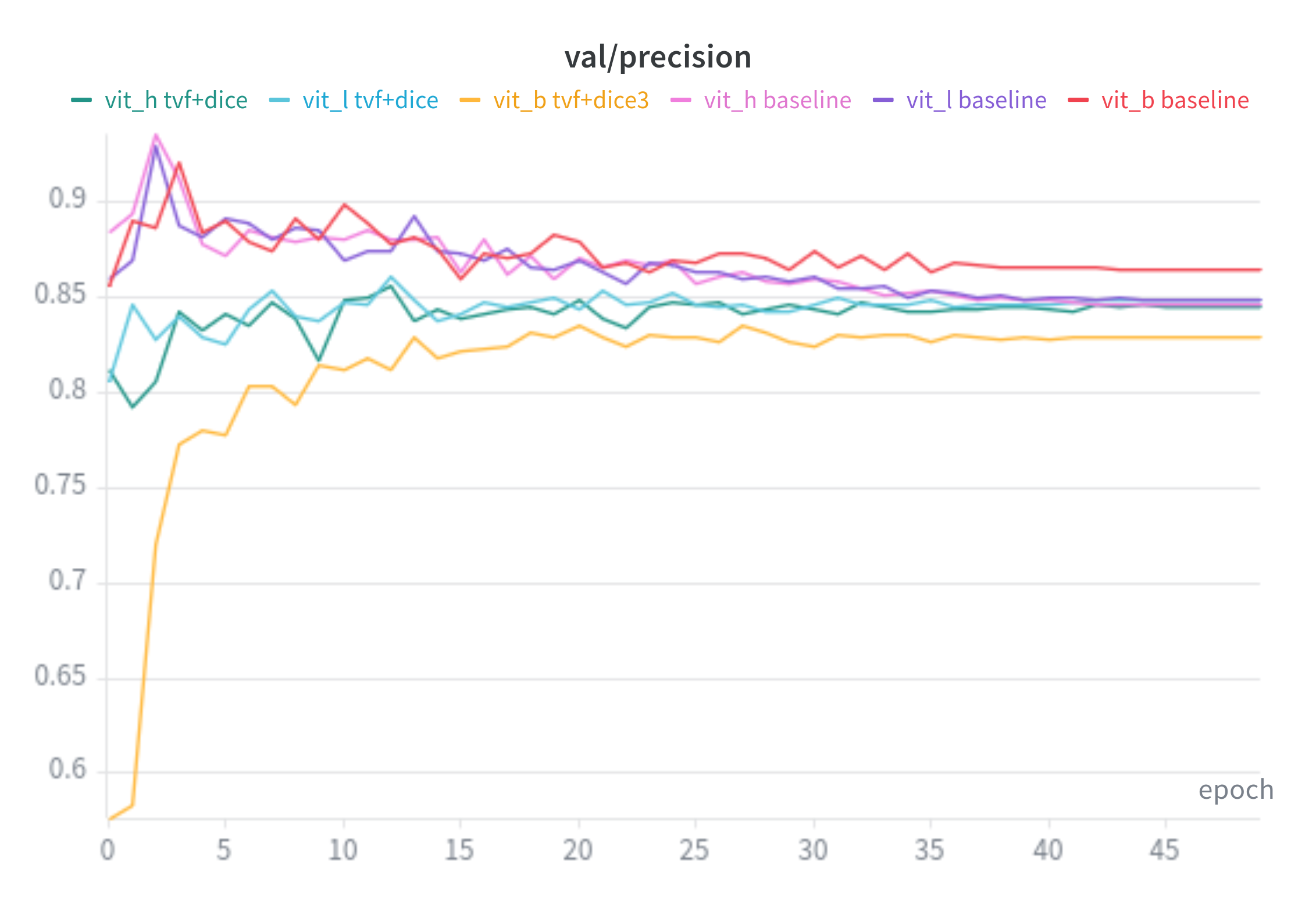
Precision:
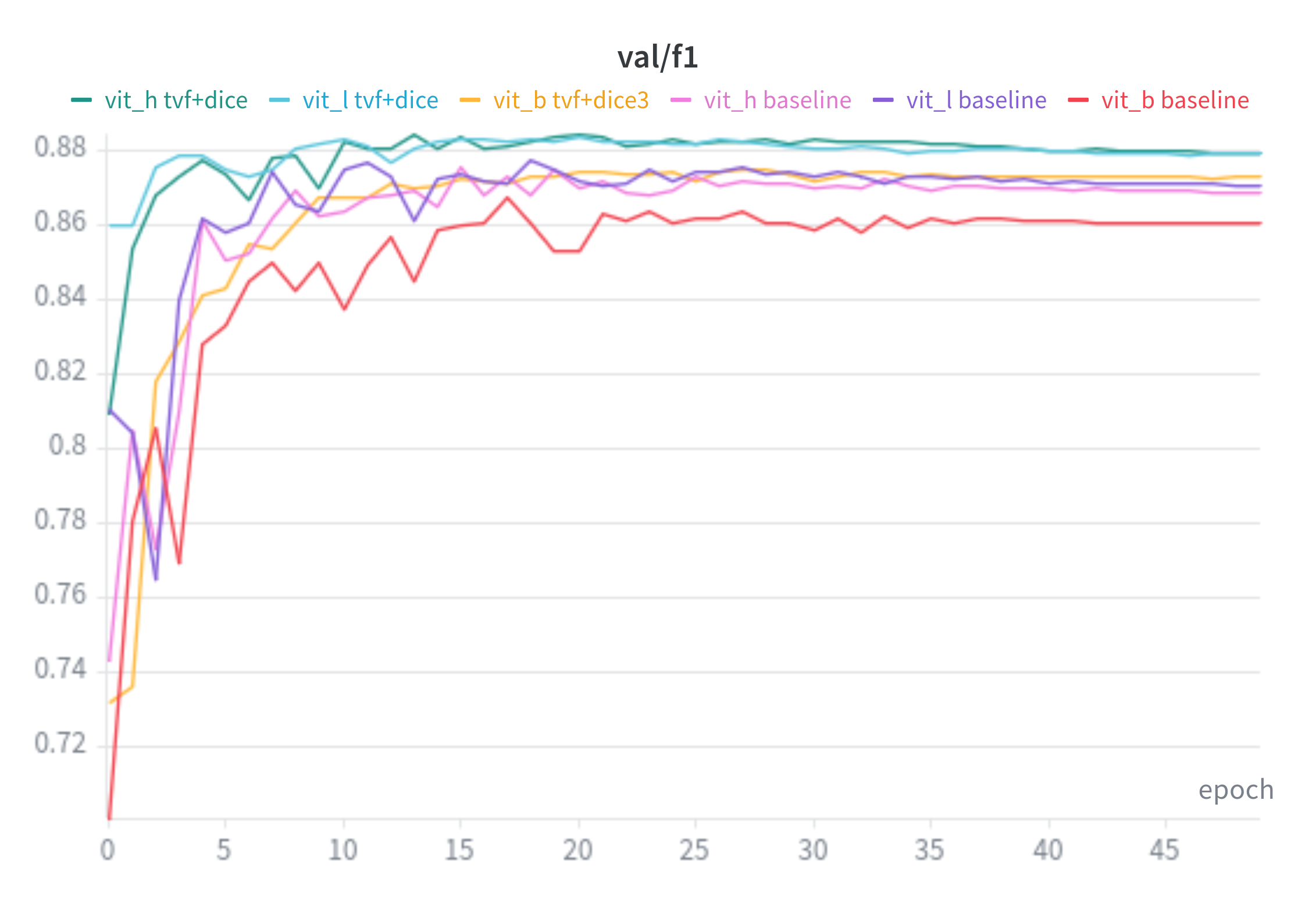
F1:
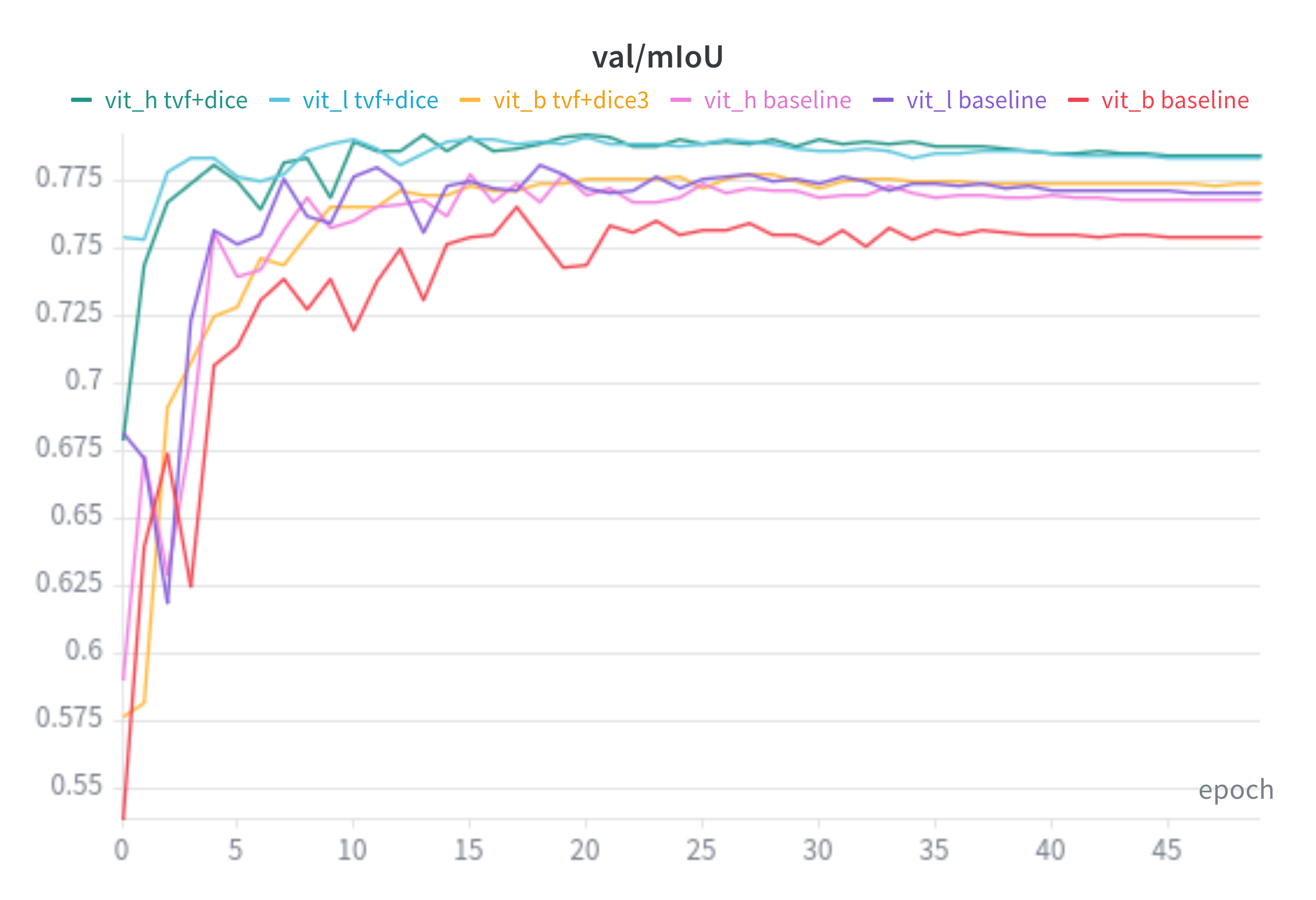
mIoU:
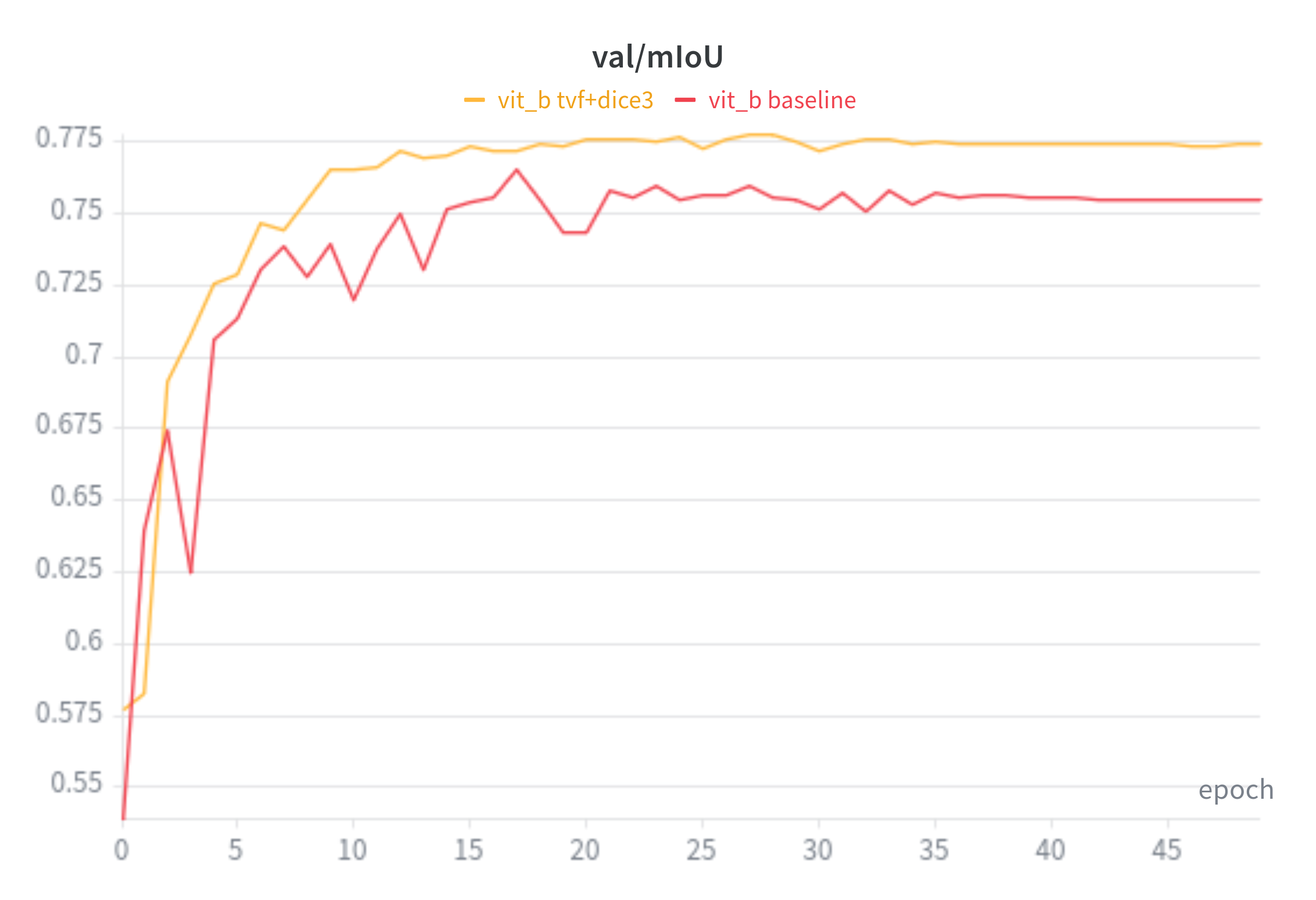
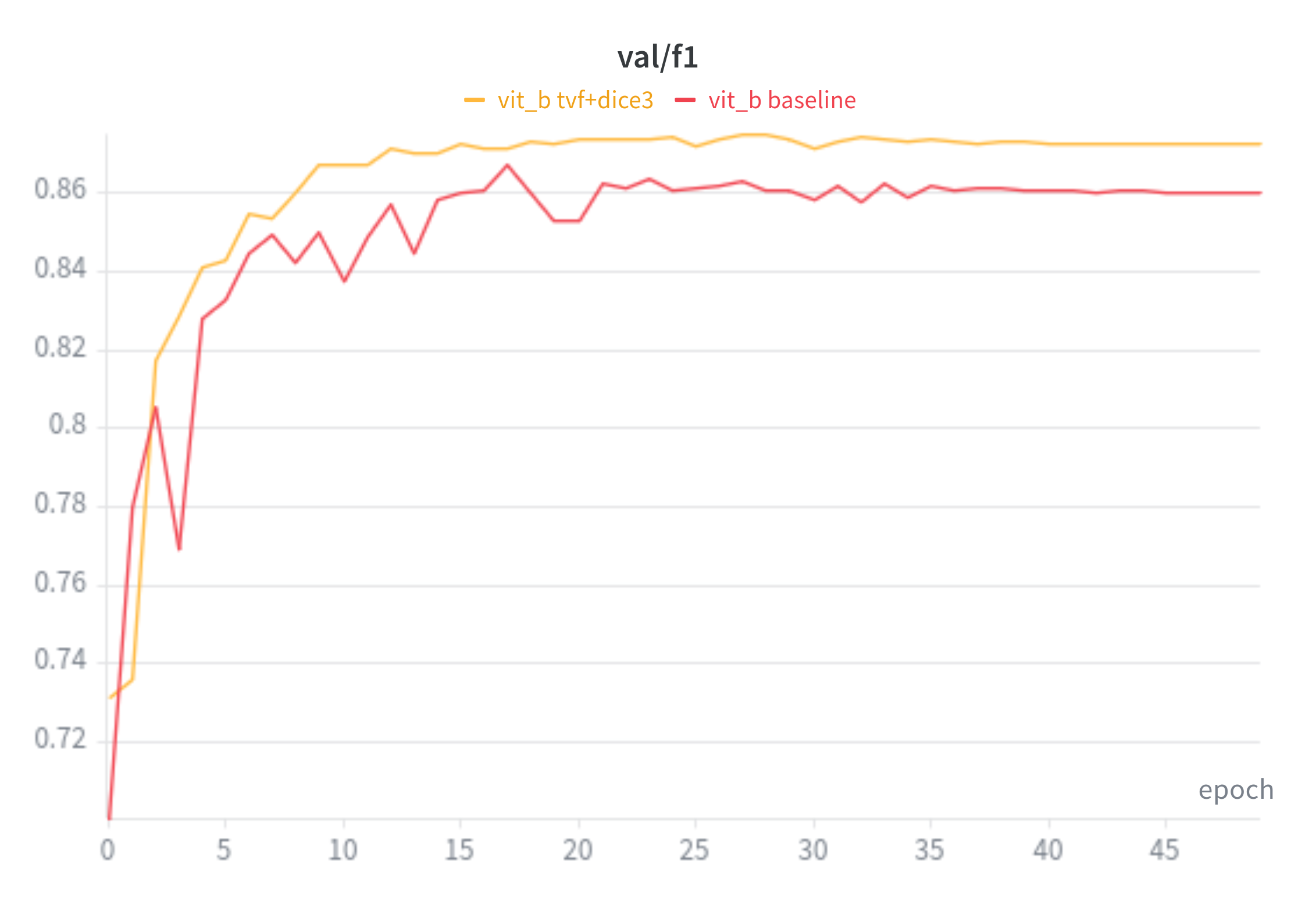
ViT-B Baseline VS TverskyFocal + Dice
mIoU:
f1:
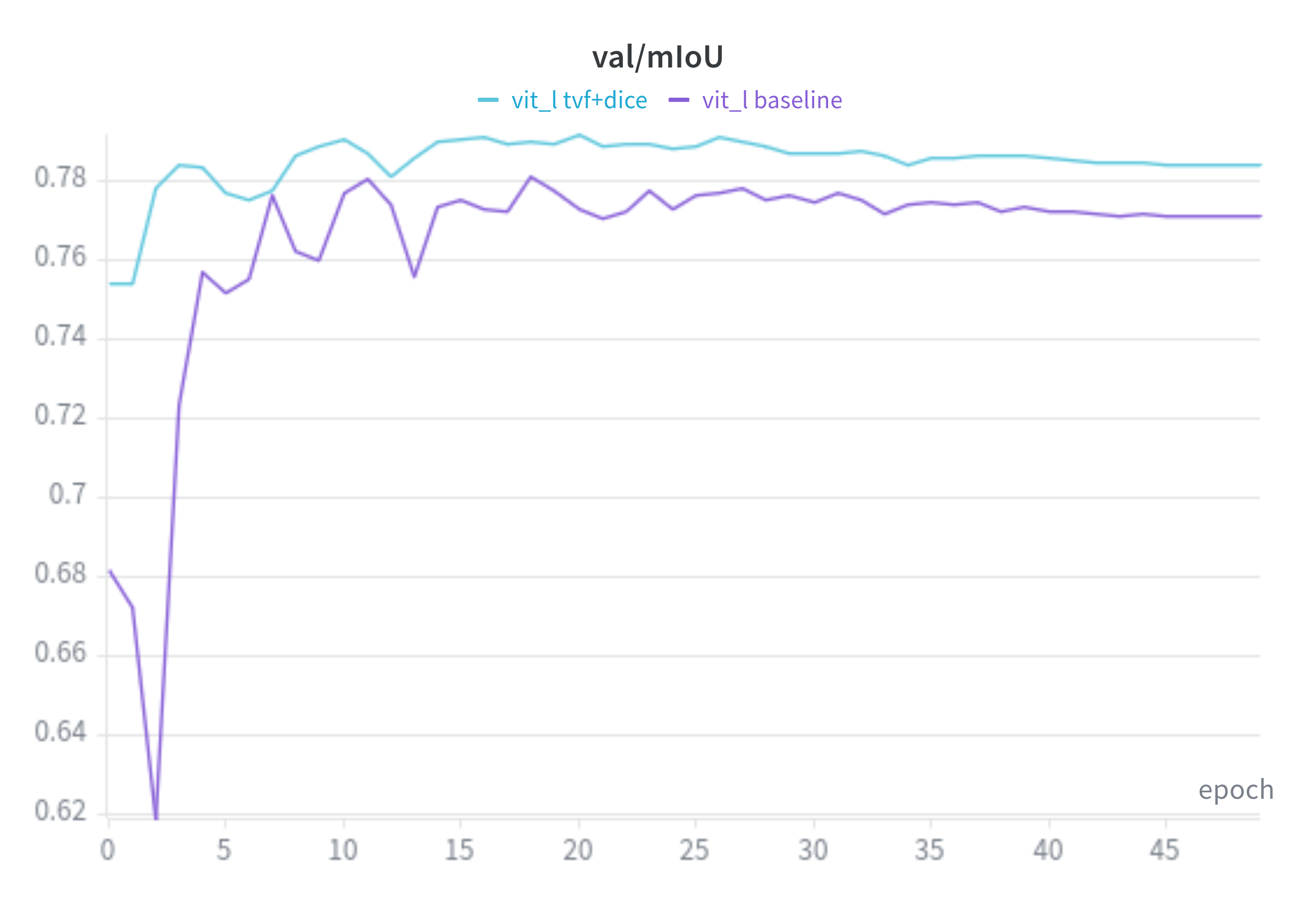
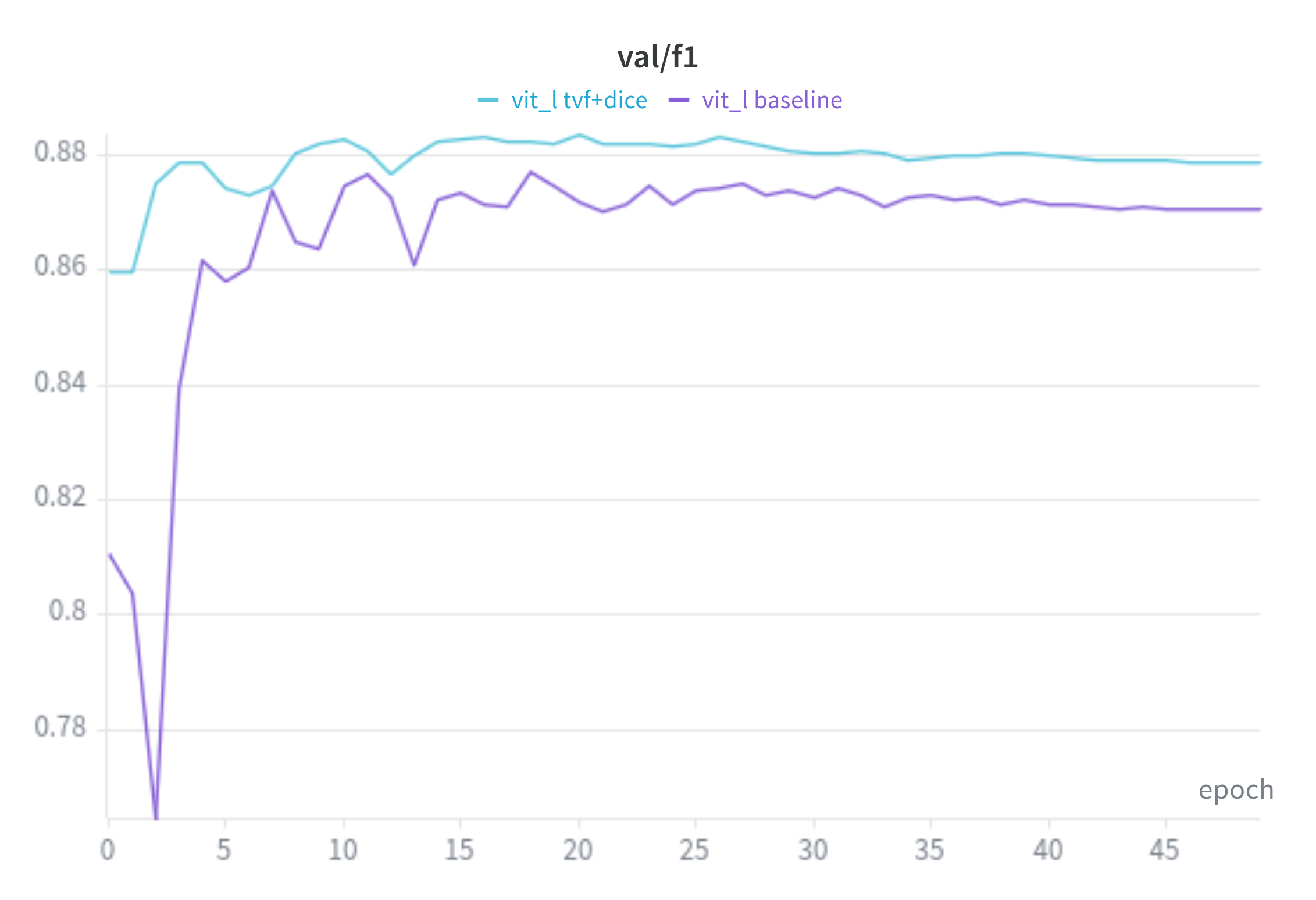
ViT-L Baseline VS TverskyFocal + Dice
mIoU:
f1:
ViT-H Baseline VS TverskyFocal + Dice
DeepLab
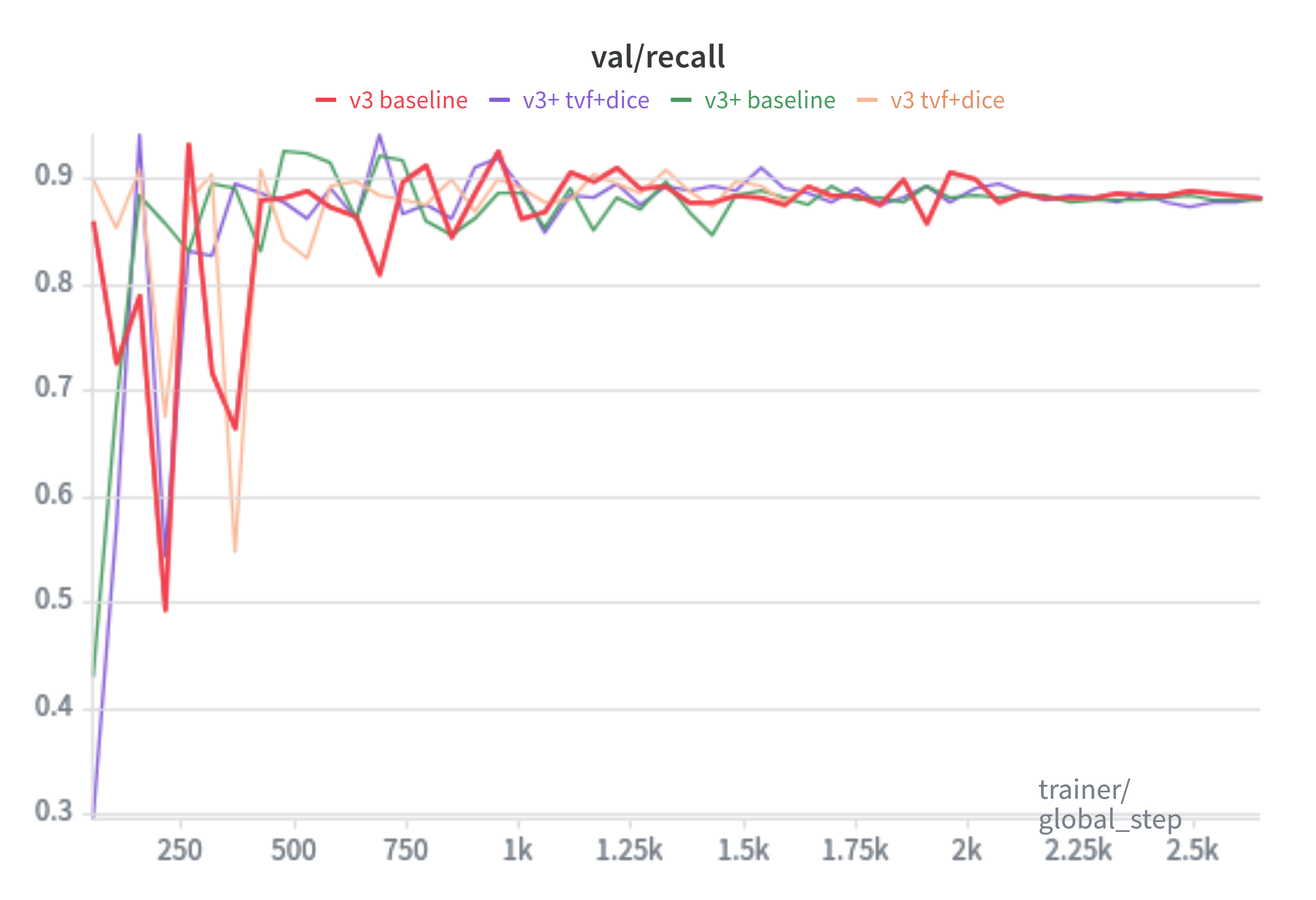
Recall:
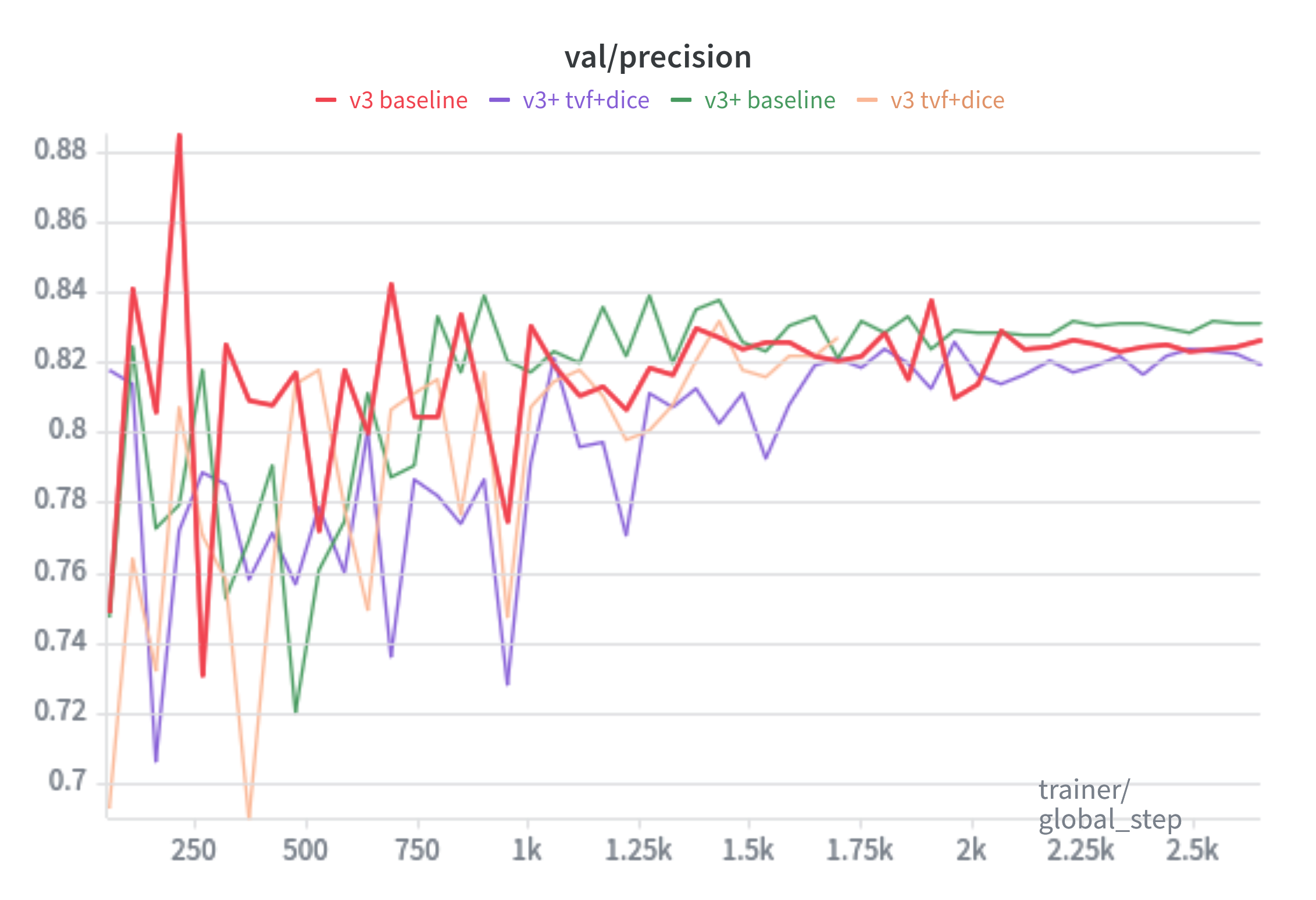
Precision:
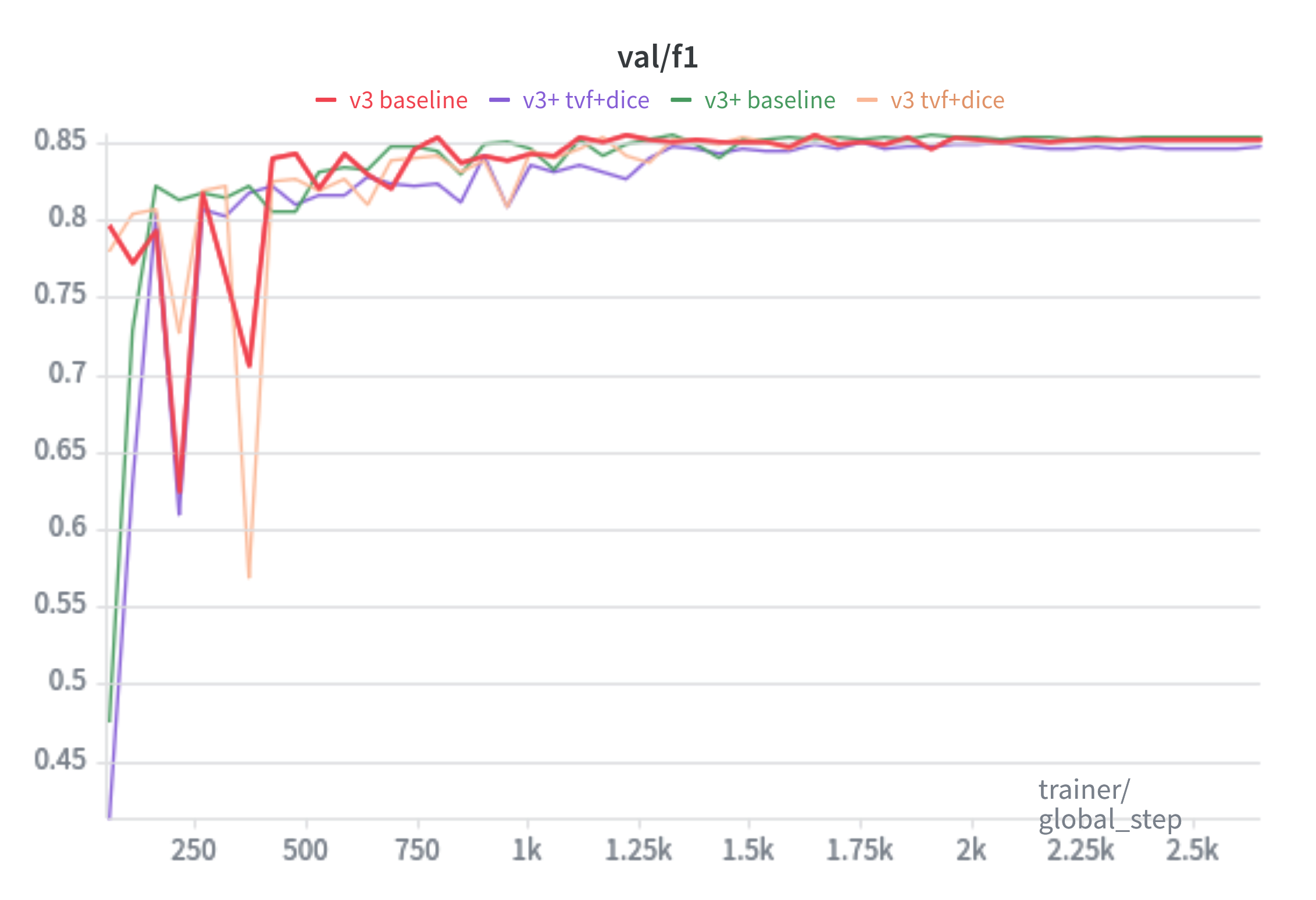
F1:
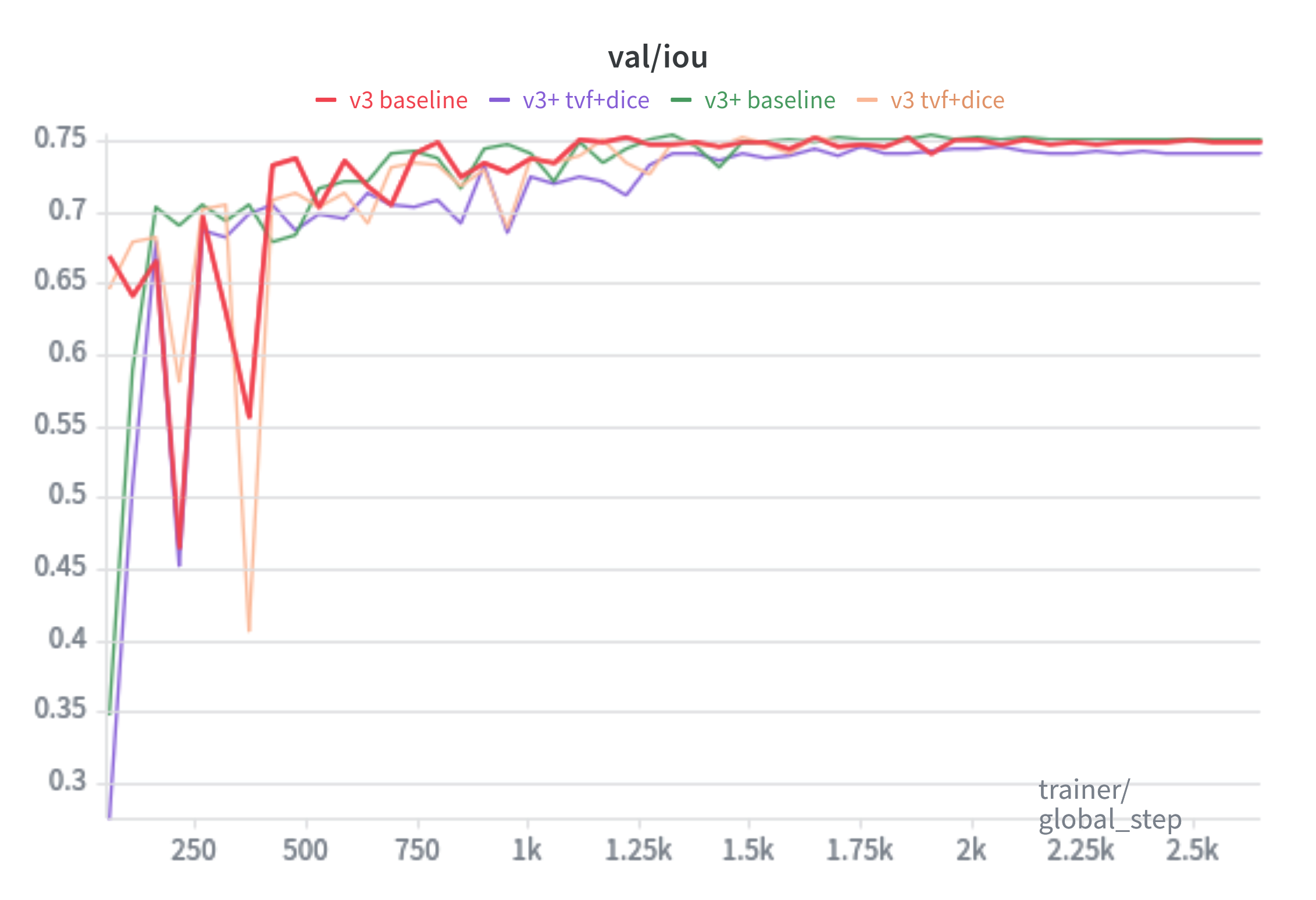
mIoU:
Test Results
Thoughts
I think for “framing”, the original paper talks about using Tvserky loss for class imbalanced datasets, but I feel like we are using it more for reducing the models bias towards over guessing(kind of same thing but maybe not?).