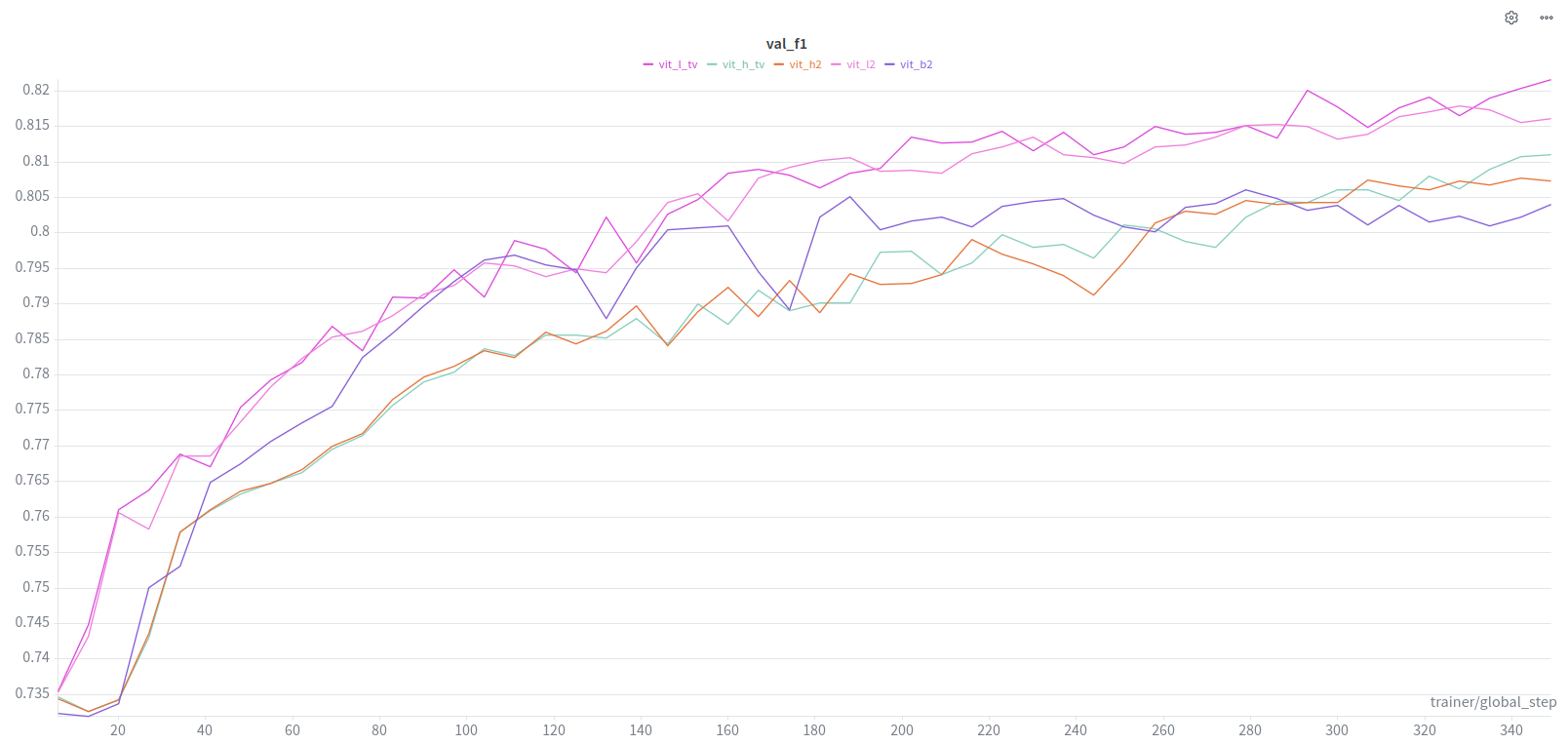
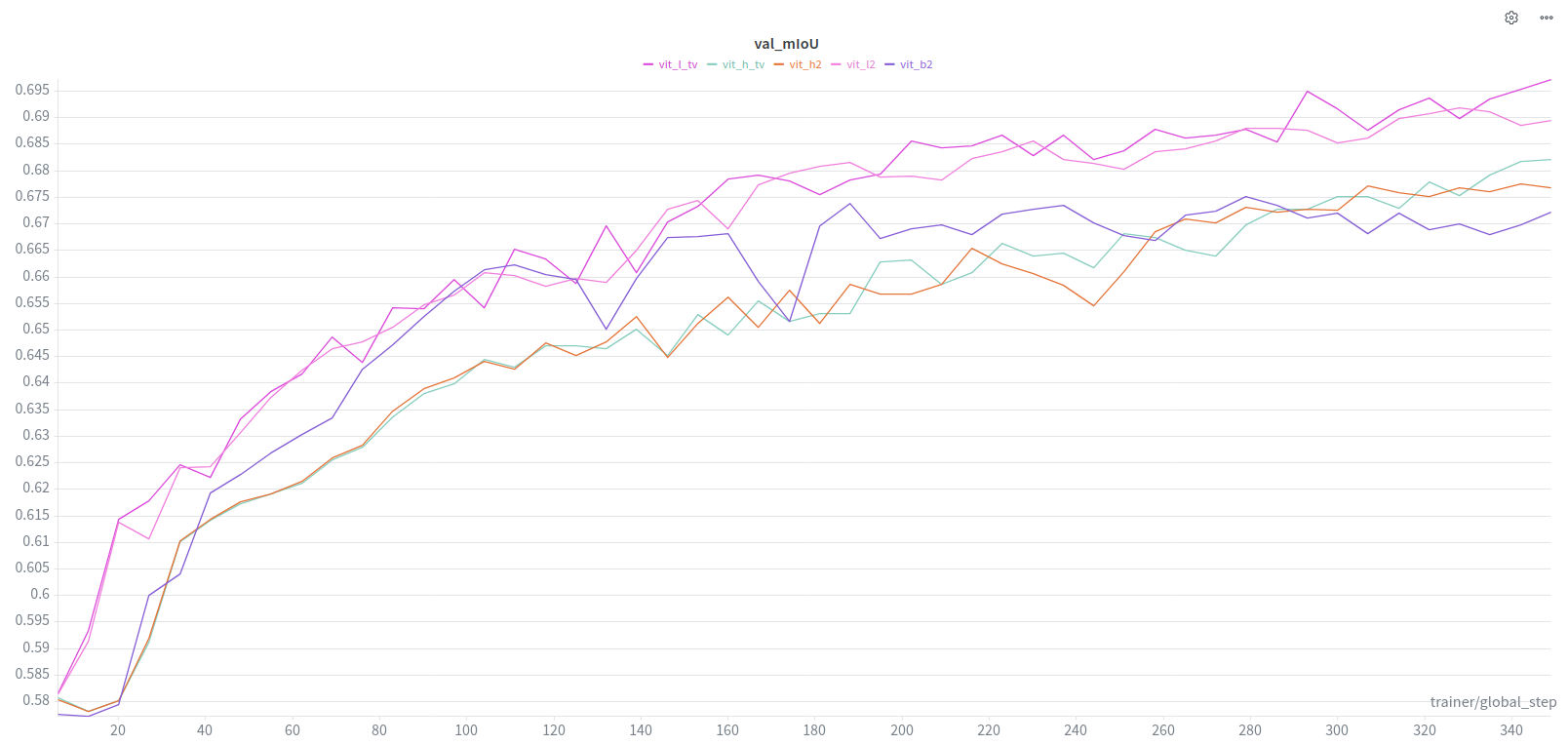
From Last Time, across all experiments, SAM models, TV Loss scales.
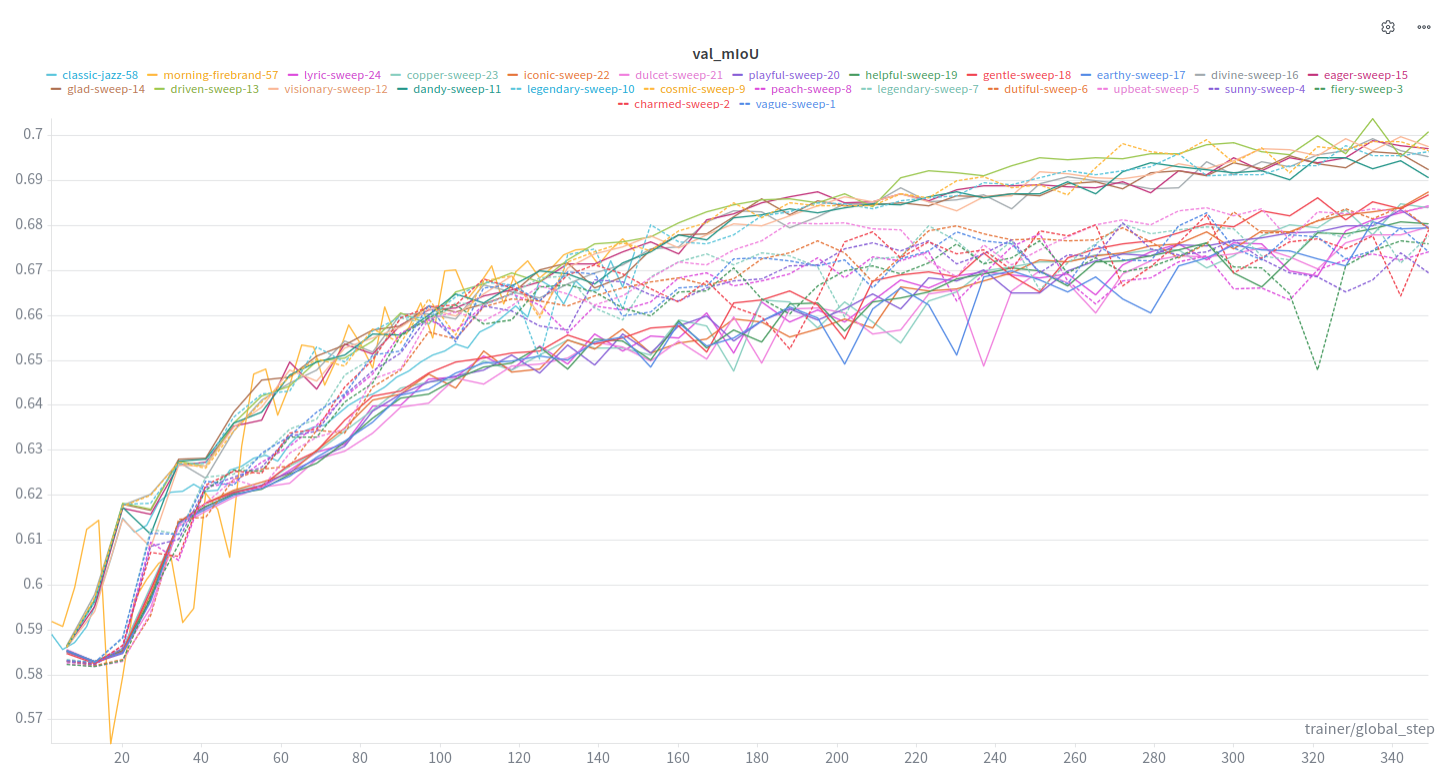
mIoU tends to converge towards .70 at the higher end.
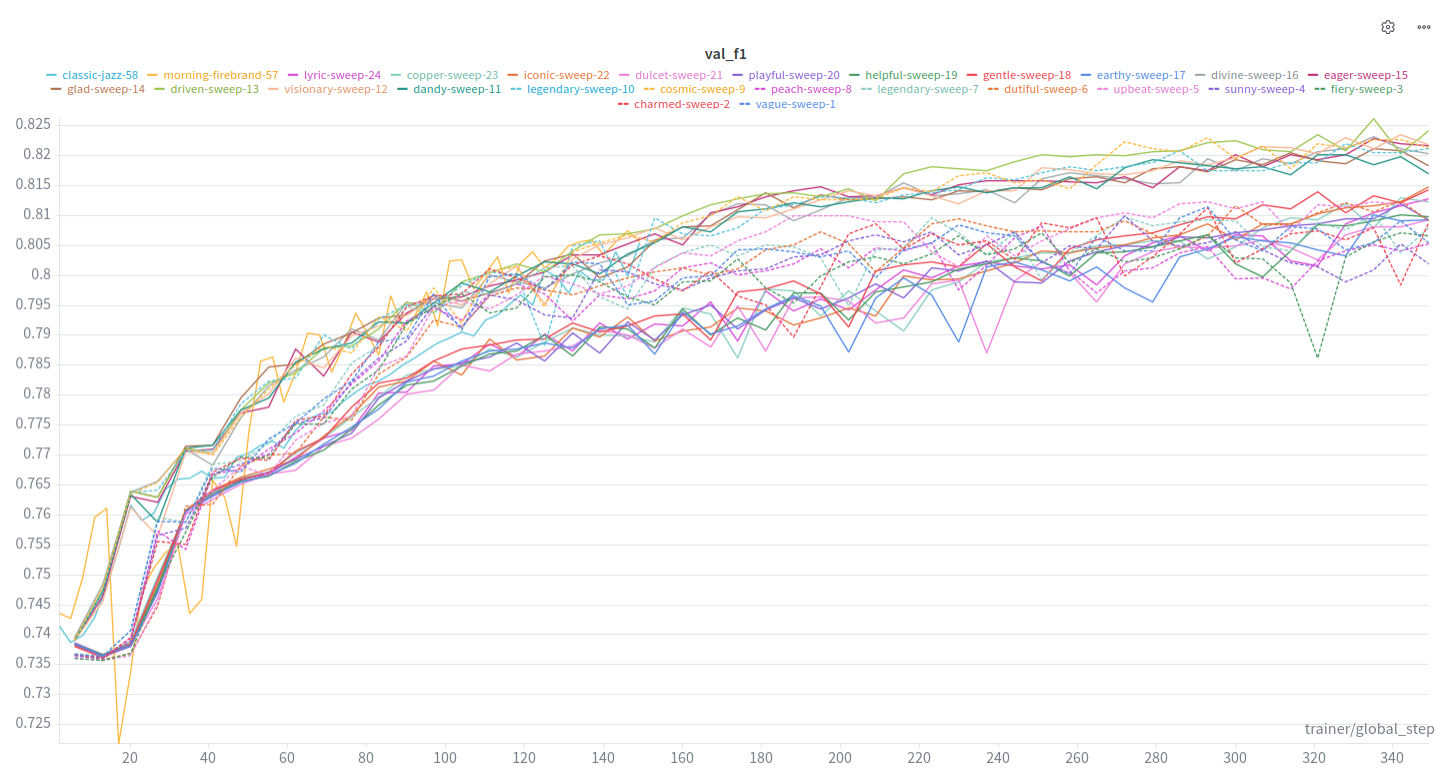
f1 tends towards .82 at the higher end.
Clean Data:
For all of the data cleaning, I added a road class(28). In the CalCROP21 source code, it’s a little weird, but they have 28 listed as one of the class but it does not get used, and 100 is instead used for the Unknown class.
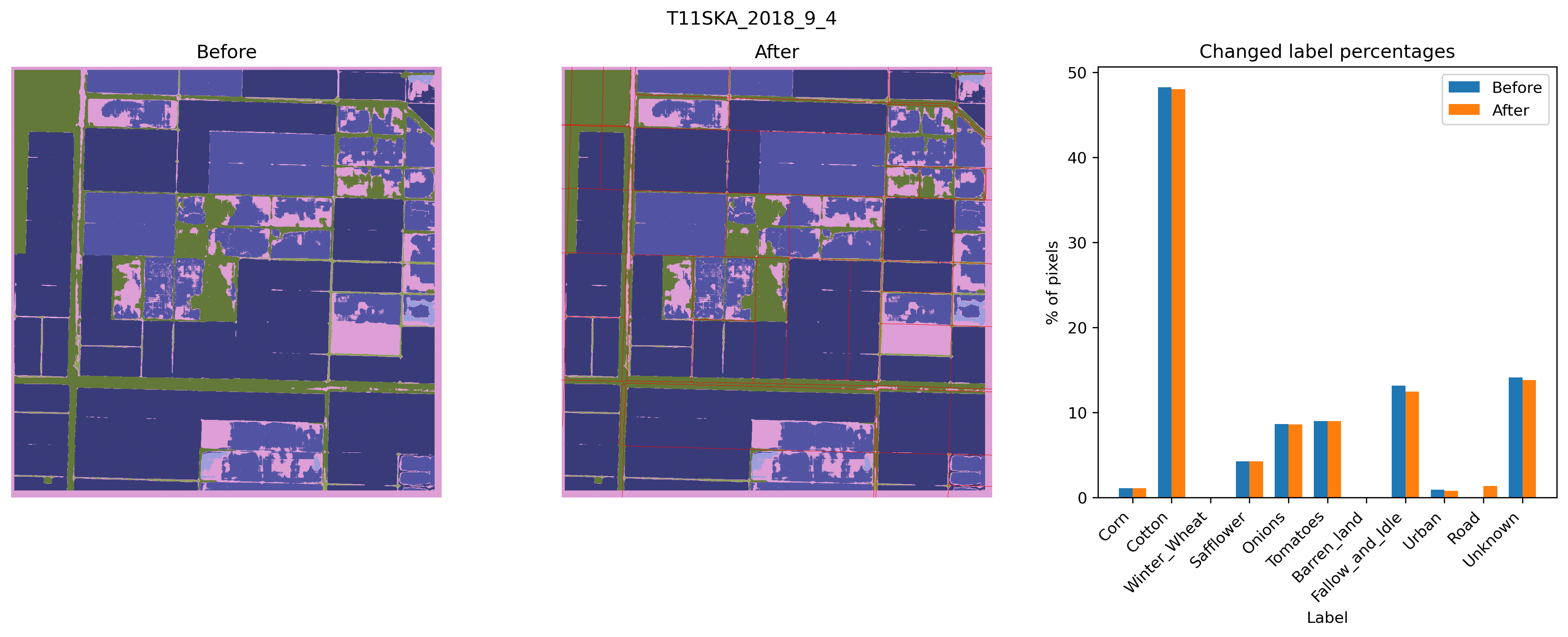
This was the best performing tile for default SAM.
This is the poorly performing tile that we normally focus on.
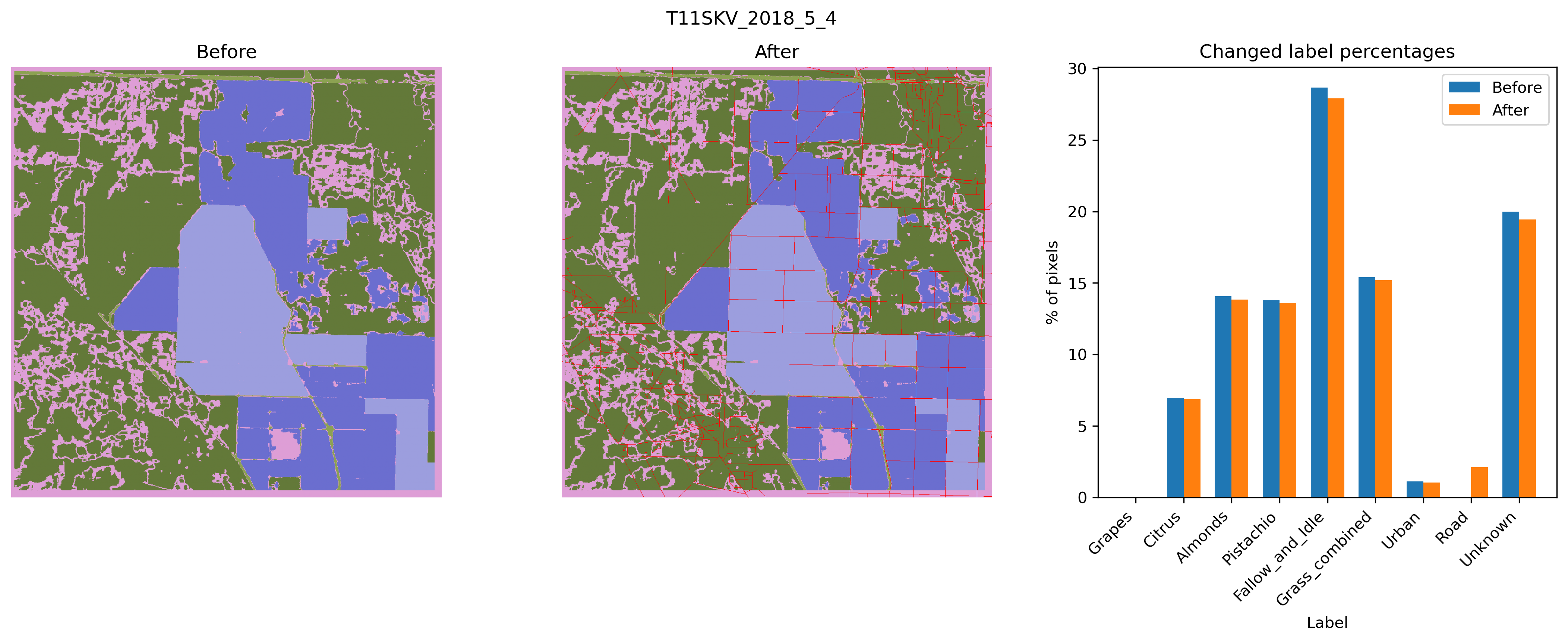
General Stats:
Visualization GT Mask Changes
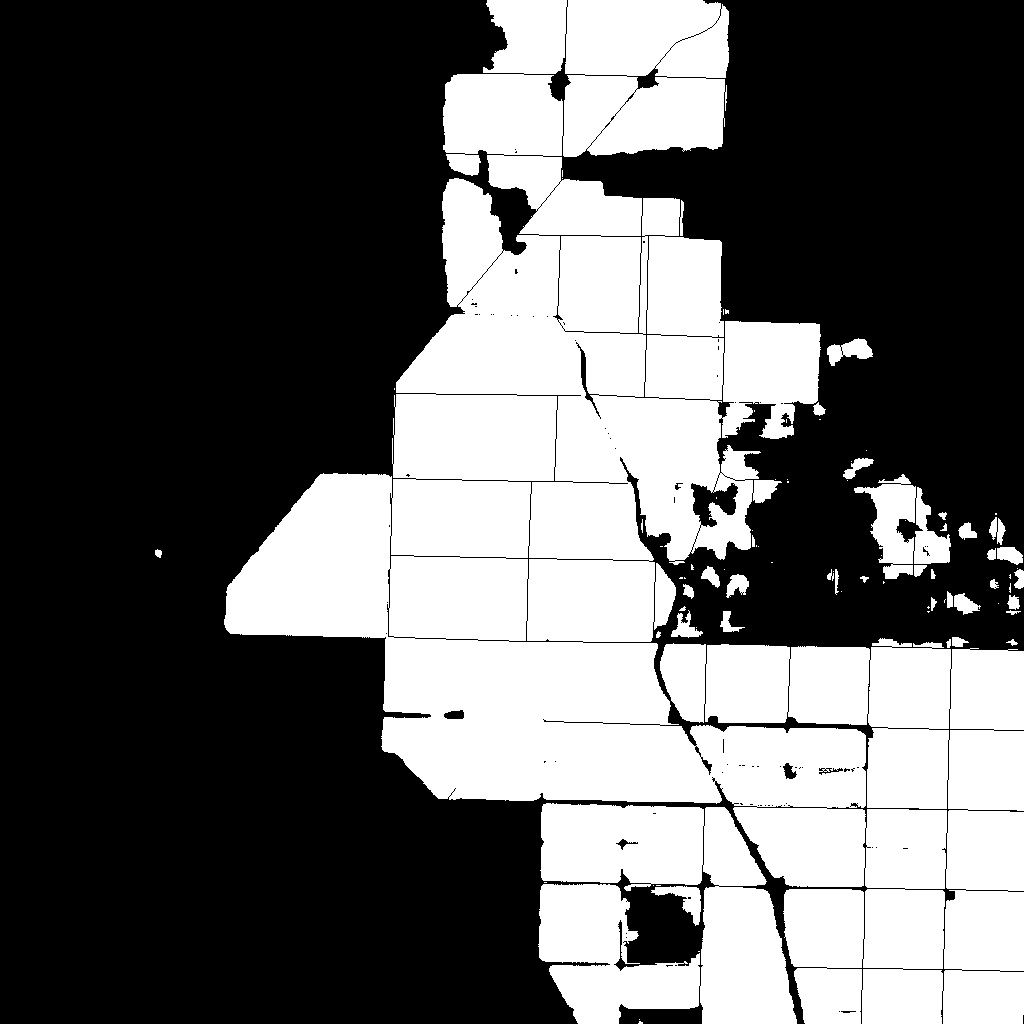
VS:
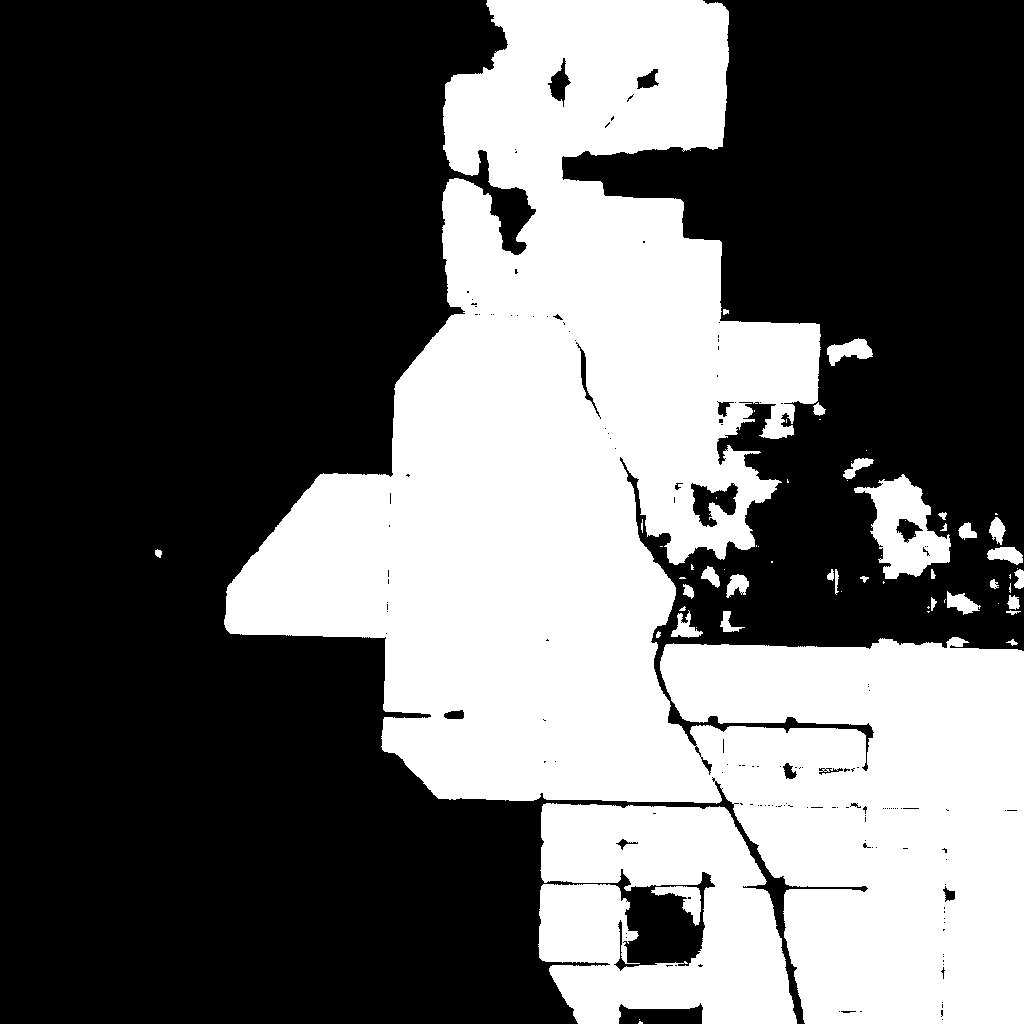
Question: Soft label updates around roads?
MobileSAM Experiments:
- Batch size 16
- Full model finetuning
- 50 Epochs(With Early Stopping)
- LR: 5e-5
- TV: 5e-3
- WD: 0.01
- Tried both cleaned/uncleaned data
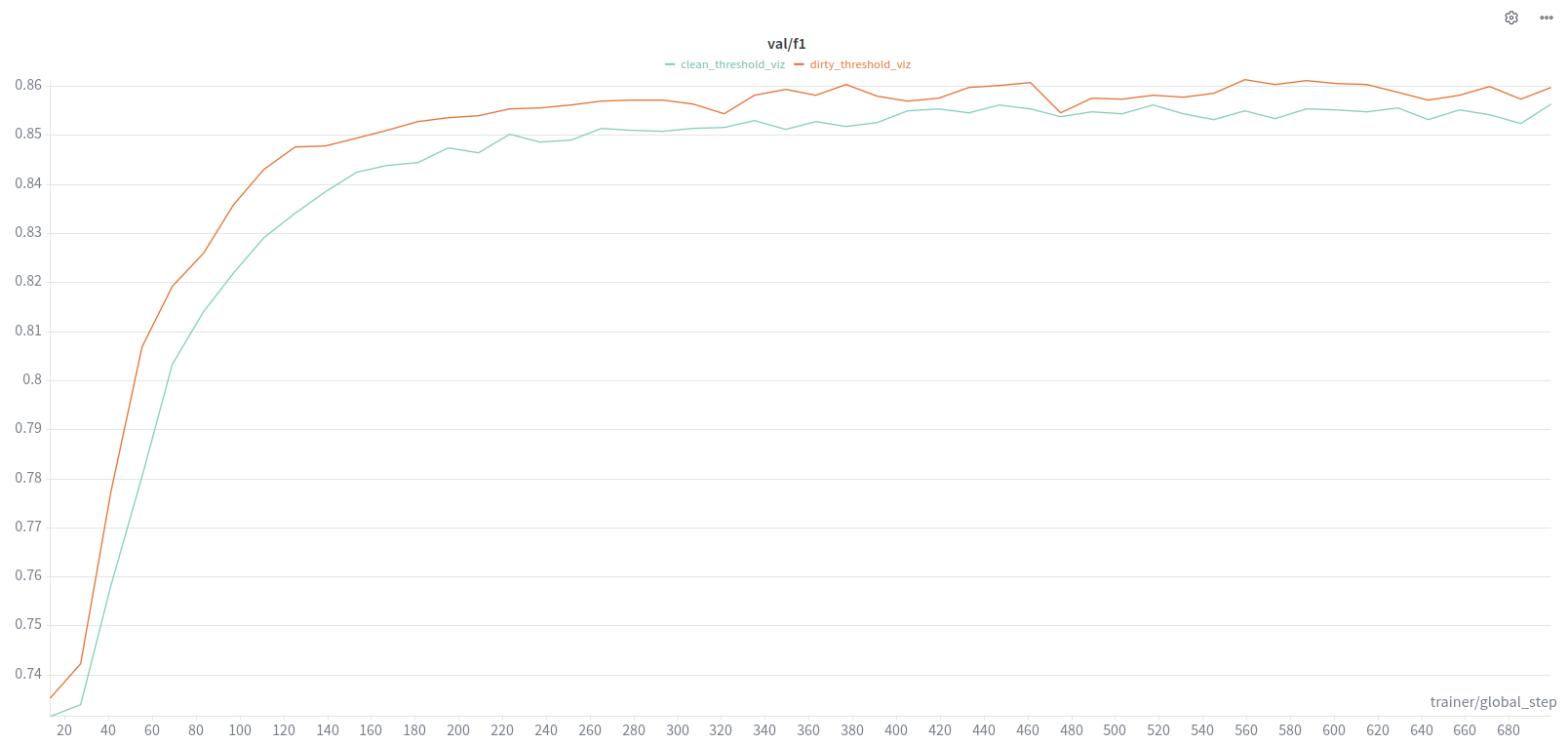
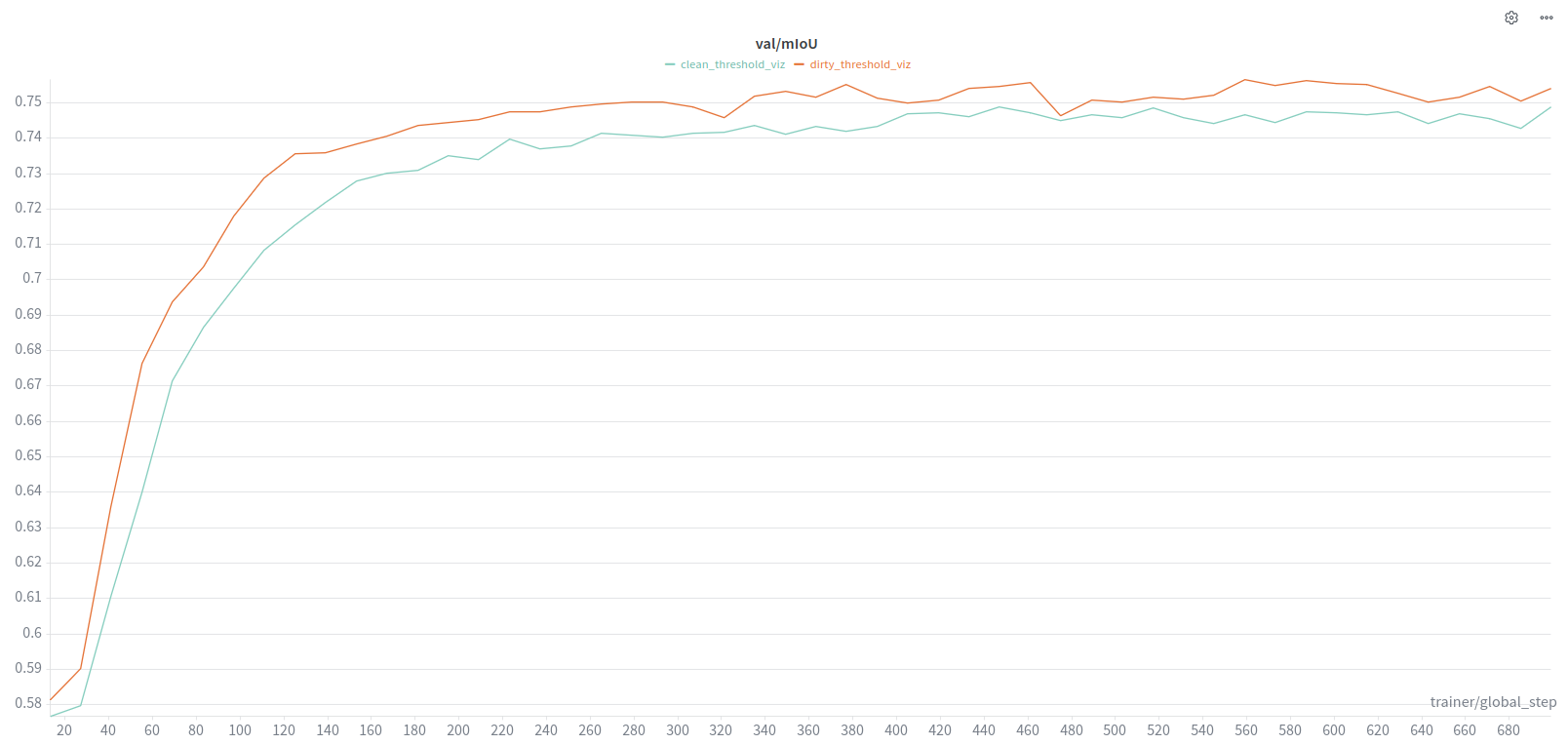
DeepLab:
- Full model finetuning
- 50 Epochs(With Early Stopping)
- LR: 5e-5
- TV: 5e-3
- WD: 0.01
- Only Cleaned Labels
V3
Paper Batch Size: 4
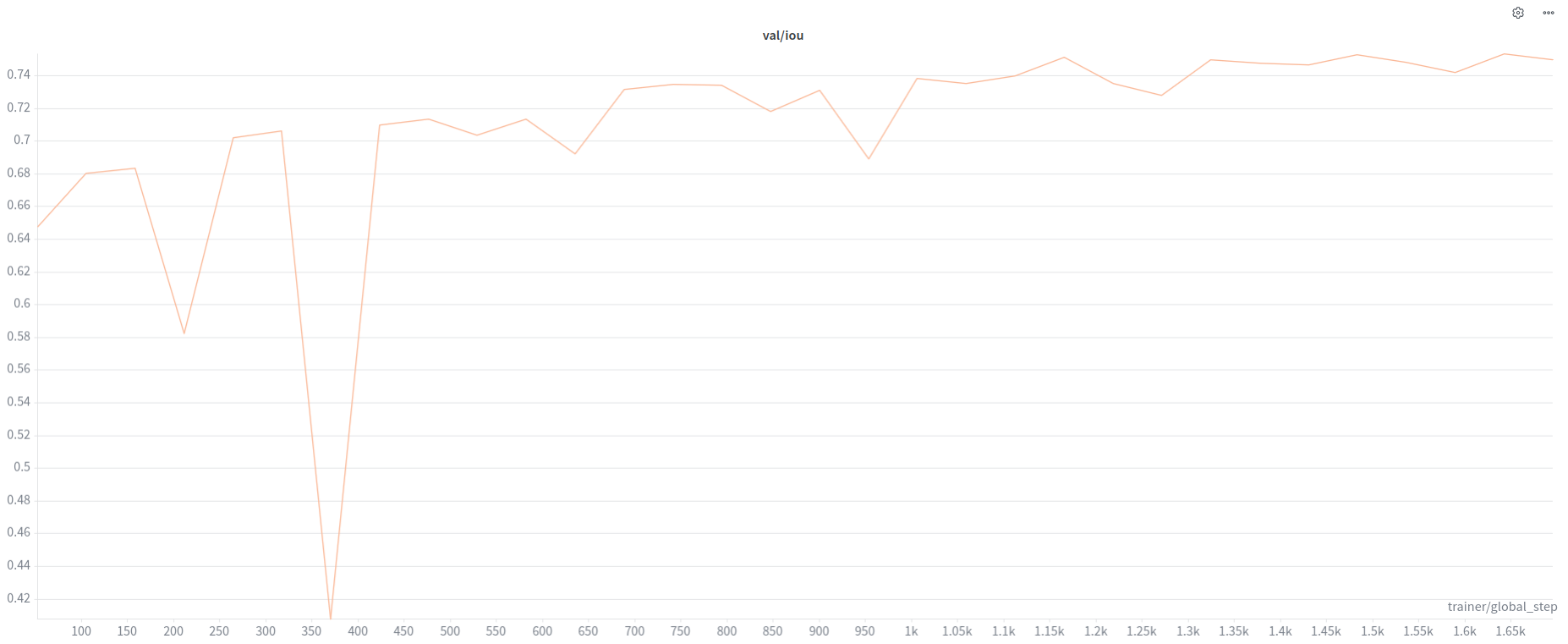
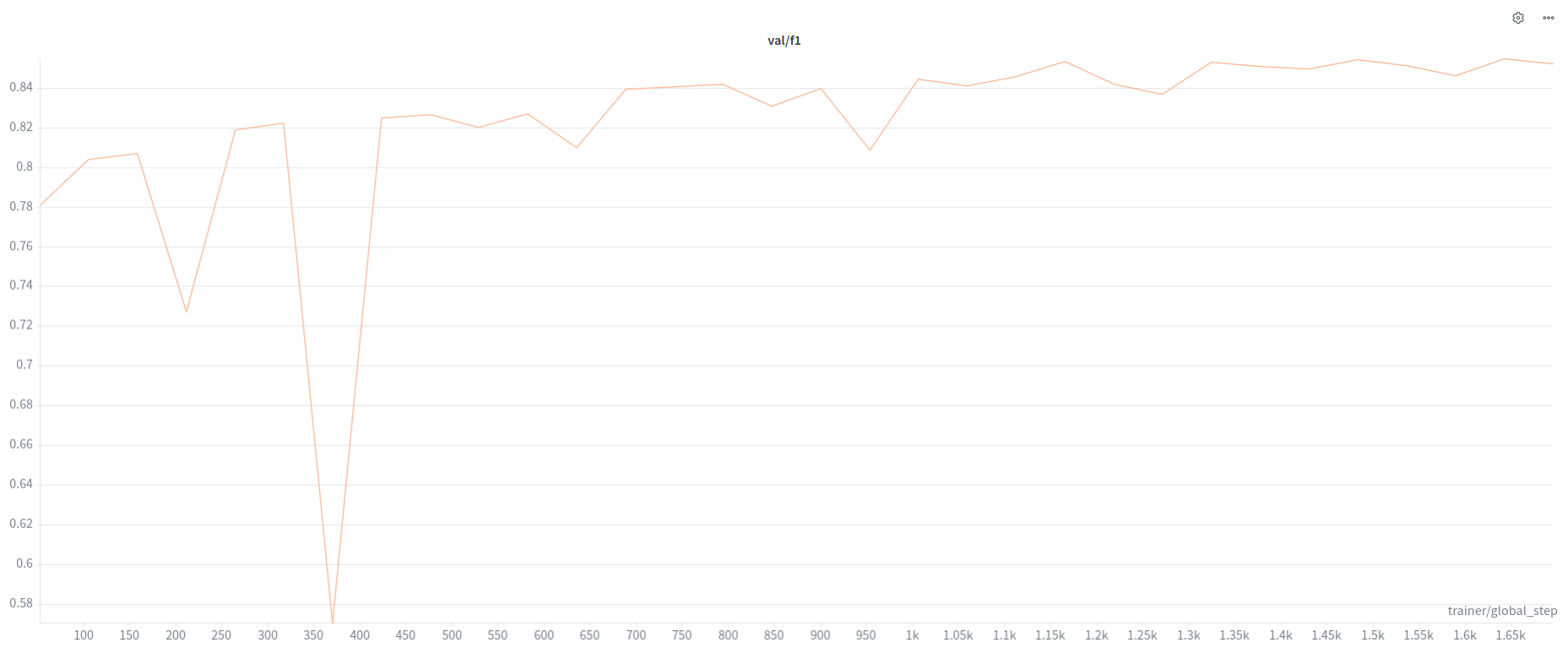
V3+
Paper Batch Size: 8
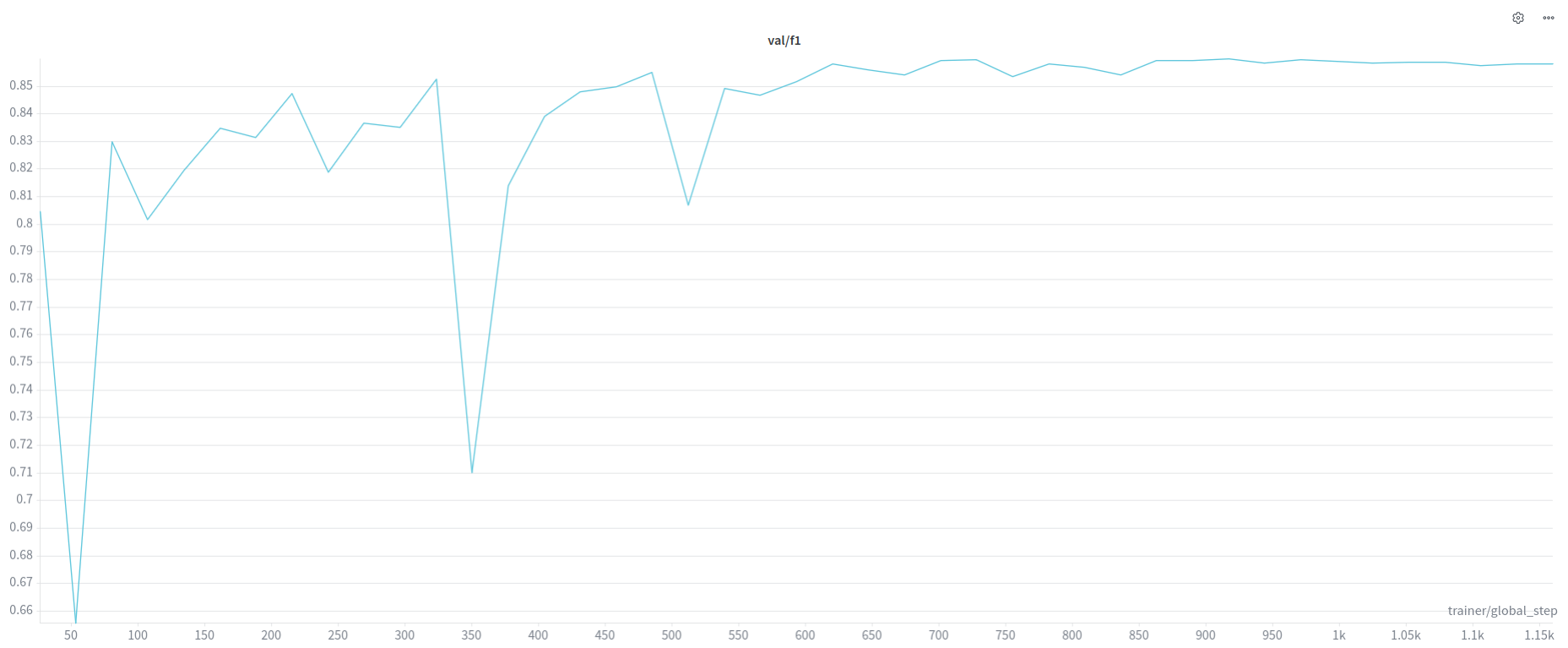
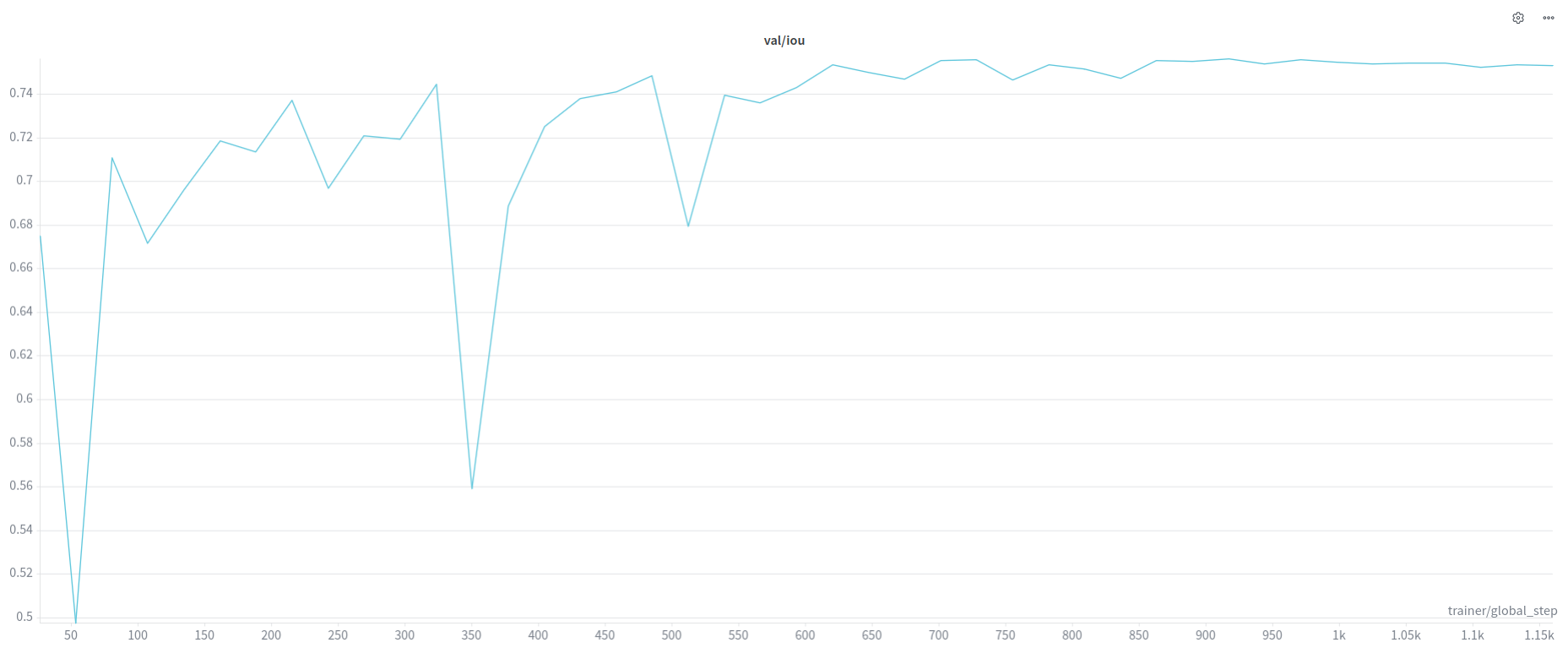
Todo:
- Test Results
- Finetune Encoder(Full SAM)
- Out-of-the-box MobileSAM + DeepLab
- Paper Writing
- Knowledge Distillation
Some Other Thoughts:

From CalCROP paper. Is it better to train on CDL(Noisy Grids) with higher TV loss added to address, or train on CalCROP(model generated grids that predict CDL grids)